https://www.cloudera.com/documentation/enterprise/5-8-x/topics/cdh_ig_yarn_tuning.html
'spark,kafka,hadoop ecosystems > yarn' 카테고리의 다른 글
| yarn 이란 (0) | 2018.11.20 |
|---|
https://www.cloudera.com/documentation/enterprise/5-8-x/topics/cdh_ig_yarn_tuning.html
| yarn 이란 (0) | 2018.11.20 |
|---|
텐서플로우(TensorFlow)는 라이브러리 이름에서 알수있듯이 텐서(Tensor)를 흘려보내면서(Flow) 데이터를 처리하는 라이브러리이다. 여기서 텐서(Tensor)는 다차원 배열을 의미한다. 텐서의 예시는 아래와 같다.
랭크*Rank는 텐서의 차원(Dimension)을 의미한다. 만약 랭크가 0이라면 스칼라, 1이라면 벡터, 2라면 행렬, 3이상이면 텐서라고 부른다.이런 텐서는 계산 그래프 구조(Computational Graph)를 통해 노드에서 노드로 이동(Flow) 한다. 따라서 텐서플로우를 이용해서 프로그램을 작성할 때는 다음의 두 과정을 거쳐야 한다.
그래프 생성
그래프 실행
그래프 생성 단계에서는 연산 과정을 그래프 형태로 표현하게 된다. 컴퓨터공학에서 말하는 그래프는 노드(Node)와 엣지(Edge)로 이루어진 자료구조이다. 텐서플로우는 노드에 연산(Operator), 변수(Variable), 상수(Constant) 등을 정의하고, 노드들간의 연결인 엣지를 통해 실제 텐서를 주고받으면서 계산을 수행한다.이제 실제 코드를 통해 텐서플로우에서 어떻게 그래프를 생성하는지 살펴보자.먼저 텐서플로우 라이브러리를 Import한다.
그 다음에 상수 형태의 노드를 두개 정의하고, 파이썬의 print 함수를 이용해서 노드의 값을 출력해 보자.
출력 결과는 다음과 같다.
여기까지는 그래프 생성이 된 것 뿐이므로 실제 결과값을 얻으려면 run 단계가 필요하다.
이제 아래와 같은 결과가 출력된다.
이제 상수의 개념을 알았으면, 다음은 placeholder에 대해서 알아보자.
y = x * 2 를 그래프를 통해서 실행한다고 하자. 입력값으로는 1,2,3,4,5를 넣고, 출력은 2,4,6,8,10을 기대한다고 하자. 이렇게 여러 입력값을 그래프에서 넣는 경우는 머신러닝에서 y=W*x + b 와 같은 그래프가 있다고 할 때, x는 학습을 위한 데이타가 된다.
즉 지금 살펴보고자 하는 데이타 타입은 학습을 위한 학습용 데이타를 위한 데이타 타입이다.
y=x*2를 정의하면 내부적으로 다음과 같은 그래프가 된다.

그러면, x에는 값을 1,2,3,4,5를 넣어서 결과값을 그래프를 통해서 계산해 내야한다. 개념적으로 보면 다음과 같다.

이렇게 학습용 데이타를 담는 그릇을 플레이스홀더(placeholder)라고 한다.
플레이스홀더에 대해서 알아보면, 플레이스 홀더의 위의 그래프에서 x 즉 입력값을 저장하는 일종의 통(버킷)이다.
tf.placeholder(dtype,shape,name) 으로 정의된다.
플레이스 홀더 정의에 사용되는 변수들을 보면
dtype : 플레이스홀더에 저장되는 데이타형이다. tf.float32와 같이 실수,정수등의 데이타 타입을 정의한다.
shape : 행렬의 차원을 정의한다. shapre=[3,3]으로 정의해주면, 이 플레이스홀더는 3x3 행렬을 저장하게 된다.
name : name은 이 플레이스 홀더의 이름을 정의한다. name에 대해서는 나중에 좀 더 자세하게 설명하도록 하겠다.
그러면 이 x에 학습용 데이타를 어떻게 넣을 것인가? 이를 피딩(feeding)이라고 한다.
다음 예제를 보자
처음 input_data=[1,2,3,4,5]으로 정의하고
다음으로 x=tf.placeholder(dtype=tf.float32) 를 이용하여, x를 float32 데이타형을 가지는 플레이스 홀더로 정의하다. shape은 편의상 생략하였다.
그리고 y=x * 2 로 그래프를 정의하였다.
세션이 실행될때, x라는 통에 값을 하나씩 집어 넣는데, (앞에서도 말했듯이 이를 피딩이라고 한다.)
sess.run(y,feed_dict={x:input_data}) 와 같이 세션을 통해서 그래프를 실행할 때, feed_dict 변수를 이용해서 플레이스홀더 x에, input_data를 피드하면, 세션에 의해서 그래프가 실행되면서 x는 feed_dict에 의해서 정해진 피드 데이타 [1,2,3,4,5]를 하나씩 읽어서 실행한다.
마지막 데이타형은 변수형으로,
y=W*x+b 라는 학습용 가설이 있을때, x가 입력데이타 였다면, W와 b는 학습을 통해서 구해야 하는 값이 된다. 이를 변수(Variable)이라고 하는데, 변수형은 Variable 형의 객체로 생성이 된다.
tf.Variable.__init__(initial_value=None, trainable=True, collections=None, validate_shape=True, caching_device=None, name=None, variable_def=None, dtype=None, expected_shape=None, import_scope=None)
변수형에 값을 넣는 것은 다음과 같이 한다.
var = tf.Variable([1,2,3,4,5], dtype=tf.float32)
아래의 예제를 보자.
우리가 기대하는 결과는 다음과 같다. y=W*x와 같은 그래프를 가지고,

x는 [1,2,3,4,5] 값을 피딩하면서, 변수 W에 지정된 2를 곱해서 결과를 내기를 바란다.
그렇지만 코드를 실행해보면 다음과 같이 에러가 출력되는 것을 확인할 수 있다.

이유는 텐서플로우에서 변수형은 그래프를 실행하기 전에 초기화를 해줘야 그 값이 변수에 지정이 된다. 
세션을 초기화 하는 순간 변수 W에 그 값이 지정되는데, 초기화를 하는 방법은 다음과 같이 변수들을 global_variables_initializer() 를 이용해서 초기화 한후, 초기화된 결과를 세션에 전달해 줘야 한다.
init = tf.global_variables_initializer()
sess.run(init)
그러면 초기화를 추가한 코드를 보자
초기화를 수행한 후, 코드를 수행해보면 다음과 같이 우리가 기대했던 결과가 출력됨을 확인할 수 있다.

Tensorframes는 스칼라와 아파치 스파크를위한 실험적인 TensorFlow 바인딩이다. TensorFrames(TensorFlow on Spark Dataframes)를 사용하면 TensorFlow 프로그램을 사용하여 Apache Spark의 DataFrames를 조작 할 수 있다.기본적인 Tensorflow의 계산 구조는 아래 그림과 같다.

placeholder 로 입력 값을 정의하고 graph 구조 안에서 연산을 수행한다.
그러면 결과값은 아래와 같이 출력된다.
Tensorframes를 사용하면 어떻게 될까?

위의 다이어그램에서 보는 것처럼 TensorFrames는 Spark DataFrames와 TensorFlow 사이에 Bridge 역할을 한다.
이를 통해 DataFrames를 가져 와서 TensorFlow 계산 그래프에 입력으로 적용 할 수 있다. TensorFrames를 사용하면 TensorFlow 계산 그래프 출력을 가져 와서 다시 DataFrames로 밀어 넣을 수 있으므로 다운 스트림 Spark 처리를 계속할 수 있다.
간단한 예제로, 갖고 있는 데이터의 컬럼에 특정 값을 더하는 아래의 연산을 살펴보자.
데이터는 RDD 기반의 dataframe으로 저장되어 있다. 데이터 형태를 보려면 우리가 익히 아는 spark 명령어를 쓰면 된다.

이제 tensorflow graph 연산을 해보자.
간단하게 코드를 설명하면,
z는 텐서이므로, 우리가 원하는 데이터 결과값을 보려면 위에서와 같이 df.show() 명령을 쓰면 된다.

| rtx 3080 - ubuntu 20.04 개발환경 설치기 (0) | 2021.01.22 |
|---|---|
| 머신러닝 족보 ! scikit learn algorithm cheat sheet (0) | 2019.09.04 |
| ML 환경 구축기 (e gpu 와 각종 드라이버 설치) (2) | 2019.04.16 |
| machine Learning Automation (0) | 2019.04.08 |
| fast cnns (yolo, R-CNN, SSD) (0) | 2019.02.12 |
| Query Type | Supported Output Modes | Notes | |
|---|---|---|---|
| Queries with aggregation | Aggregation on event-time with watermark | Append, Update, Complete | Append mode uses watermark to drop old aggregation state. But the output of a windowed aggregation is delayed the late threshold specified in `withWatermark()` as by the modes semantics, rows can be added to the Result Table only once after they are finalized (i.e. after watermark is crossed). See the Late Data section for more details. Update mode uses watermark to drop old aggregation state. Complete mode does not drop old aggregation state since by definition this mode preserves all data in the Result Table. |
| Other aggregations | Complete, Update | Since no watermark is defined (only defined in other category), old aggregation state is not dropped. Append mode is not supported as aggregates can update thus violating the semantics of this mode. | |
Queries with mapGroupsWithState | Update | ||
Queries with flatMapGroupsWithState | Append operation mode | Append | Aggregations are allowed after flatMapGroupsWithState. |
| Update operation mode | Update | Aggregations not allowed after flatMapGroupsWithState. | |
Queries with joins | Append | Update and Complete mode not supported yet. See the support matrix in the Join Operations section for more details on what types of joins are supported. | |
| Other queries | Append, Update | Complete mode not supported as it is infeasible to keep all unaggregated data in the Result Table. | |
There are a few types of built-in output sinks.
File sink - Stores the output to a directory.
Kafka sink - Stores the output to one or more topics in Kafka.
Foreach sink - Runs arbitrary computation on the records in the output. See later in the section for more details.
Console sink(for debugging) - Prints the output to the console/stdout every time there is a trigger. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory after every trigger.
Memory sink (for debugging) - The output is stored in memory as an in-memory table. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory. Hence, use it with caution.
Some sinks are not fault-tolerant because they do not guarantee persistence of the output and are meant for debugging purposes only. See the earlier section on fault-tolerance semantics. Here are the details of all the sinks in Spark.
Sink | Supported Output Modes | Options | Fault-tolerant | Notes |
|---|---|---|---|---|
| File Sink | Append | path: path to the output directory, must be specified. For file-format-specific options, see the related methods in DataFrameWriter (Scala/Java/Python/R). E.g. for "parquet" format options see DataFrameWriter.parquet() | Yes (exactly-once) | Supports writes to partitioned tables. Partitioning by time may be useful. |
| Kafka Sink | Append, Update, Complete | See the Kafka Integration Guide | Yes (at-least-once) | More details in the Kafka Integration Guide |
| Foreach Sink | Append, Update, Complete | None | Depends on ForeachWriter implementation | More details in the next section |
| Console Sink | Append, Update, Complete | numRows: Number of rows to print every trigger (default: 20) truncate: Whether to truncate the output if too long (default: true) | No | |
| Memory Sink | Append, Complete | None | No. But in Complete Mode, restarted query will recreate the full table. | Table name is the query name. |
| spark 재설치 (0) | 2018.11.21 |
|---|---|
| etl 통테 결과 (0) | 2018.11.21 |
| Spark Struct Streaming - joins (0) | 2018.11.20 |
| Spark Struct Streaming - other operations (0) | 2018.11.20 |
| spark struct streaming - window operation (0) | 2018.11.20 |
2.3.0 부터 지원된다.,
(IPC - 2.2.0 , EPC 2.3.0)
| Left Input | Right Input | Join Type | |
|---|---|---|---|
| Static | Static | All types | Supported, since its not on streaming data even though it can be present in a streaming query |
| Stream | Static | Inner | Supported, not stateful |
| Left Outer | Supported, not stateful | ||
| Right Outer | Not supported | ||
| Full Outer | Not supported | ||
| Static | Stream | Inner | Supported, not stateful |
| Left Outer | Not supported | ||
| Right Outer | Supported, not stateful | ||
| Full Outer | Not supported | ||
| Stream | Stream | Inner | Supported, optionally specify watermark on both sides + time constraints for state cleanup |
| Left Outer | Conditionally supported, must specify watermark on right + time constraints for correct results, optionally specify watermark on left for all state cleanup | ||
| Right Outer | Conditionally supported, must specify watermark on left + time constraints for correct results, optionally specify watermark on right for all state cleanup | ||
| Full Outer | Not supported |
정리하자면, STREAM - STREAM JOIN 에서 INNER 조인은 watermark 가 옵셔날이지만 의미적으로도 써주는것이 좋고 성능도개선된다.
OUTER 조인은 Watermark 가 필수인데 ,그이유는 마지막까지 조인할 대상을 찾고 기다리기 때문에, 만약 null 일 경우 delay time 은 최대가된다.
Joins can be cascaded, that is, you can do df1.join(df2, ...).join(df3, ...).join(df4, ....).
As of Spark 2.3, you can use joins only when the query is in Append output mode. Other output modes are not yet supported.
As of Spark 2.3, you cannot use other non-map-like operations before joins. Here are a few examples of what cannot be used.
Cannot use streaming aggregations before joins.
Cannot use mapGroupsWithState and flatMapGroupsWithState in Update mode before joins.
| etl 통테 결과 (0) | 2018.11.21 |
|---|---|
| Spark Struct Streaming - output (0) | 2018.11.20 |
| Spark Struct Streaming - other operations (0) | 2018.11.20 |
| spark struct streaming - window operation (0) | 2018.11.20 |
| Spark Struct Streaming - intro (0) | 2018.11.20 |
deduplication
watermark - watermark 까지 (참고로 이전 date 는 중복제거가 안 될 수 있음)
without - sate 되는대까지
mapGroupsWithState and the more powerful operation flatMapGroupsWithState. Both operations allow you to apply user-defined code on grouped Datasets to update user-defined state. For more concrete details, take a look at the API documentation (Scala/Java) and the examples (Scala/Java).3. Unsupported!
There are a few DataFrame/Dataset operations that are not supported with streaming DataFrames/Datasets. Some of them are as follows.
Multiple streaming aggregations (i.e. a chain of aggregations on a streaming DF) are not yet supported on streaming Datasets.
Limit and take first N rows are not supported on streaming Datasets.
Distinct operations on streaming Datasets are not supported.
Sorting operations are supported on streaming Datasets only after an aggregation and in Complete Output Mode.
Few types of outer joins on streaming Datasets are not supported. See the support matrix in the Join Operations section for more details.
In addition, there are some Dataset methods that will not work on streaming Datasets. They are actions that will immediately run queries and return results, which does not make sense on a streaming Dataset. Rather, those functionalities can be done by explicitly starting a streaming query (see the next section regarding that).
count() - Cannot return a single count from a streaming Dataset. Instead, use ds.groupBy().count() which returns a streaming Dataset containing a running count.
foreach() - Instead use ds.writeStream.foreach(...) (see next section).
show() - Instead use the console sink (see next section).
| Spark Struct Streaming - output (0) | 2018.11.20 |
|---|---|
| Spark Struct Streaming - joins (0) | 2018.11.20 |
| spark struct streaming - window operation (0) | 2018.11.20 |
| Spark Struct Streaming - intro (0) | 2018.11.20 |
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
Window Operations on Event Time
Aggregations over a sliding event-time window are straightforward with Structured Streaming and are very similar to grouped aggregations. In a grouped aggregation, aggregate values (e.g. counts) are maintained for each unique value in the user-specified grouping column. In case of window-based aggregations, aggregate values are maintained for each window the event-time of a row falls into. Let’s understand this with an illustration.
>>Aggeregation 과정은 Structured Streaming 에서 똑바르며 grouped aggregation 과 유사하다. 다만 grouped aggregation 에서는 특정컬럼을 기준으로 정리되는데 window - based aggregation 은 Event time 을기준으로 정리된다. 된다.
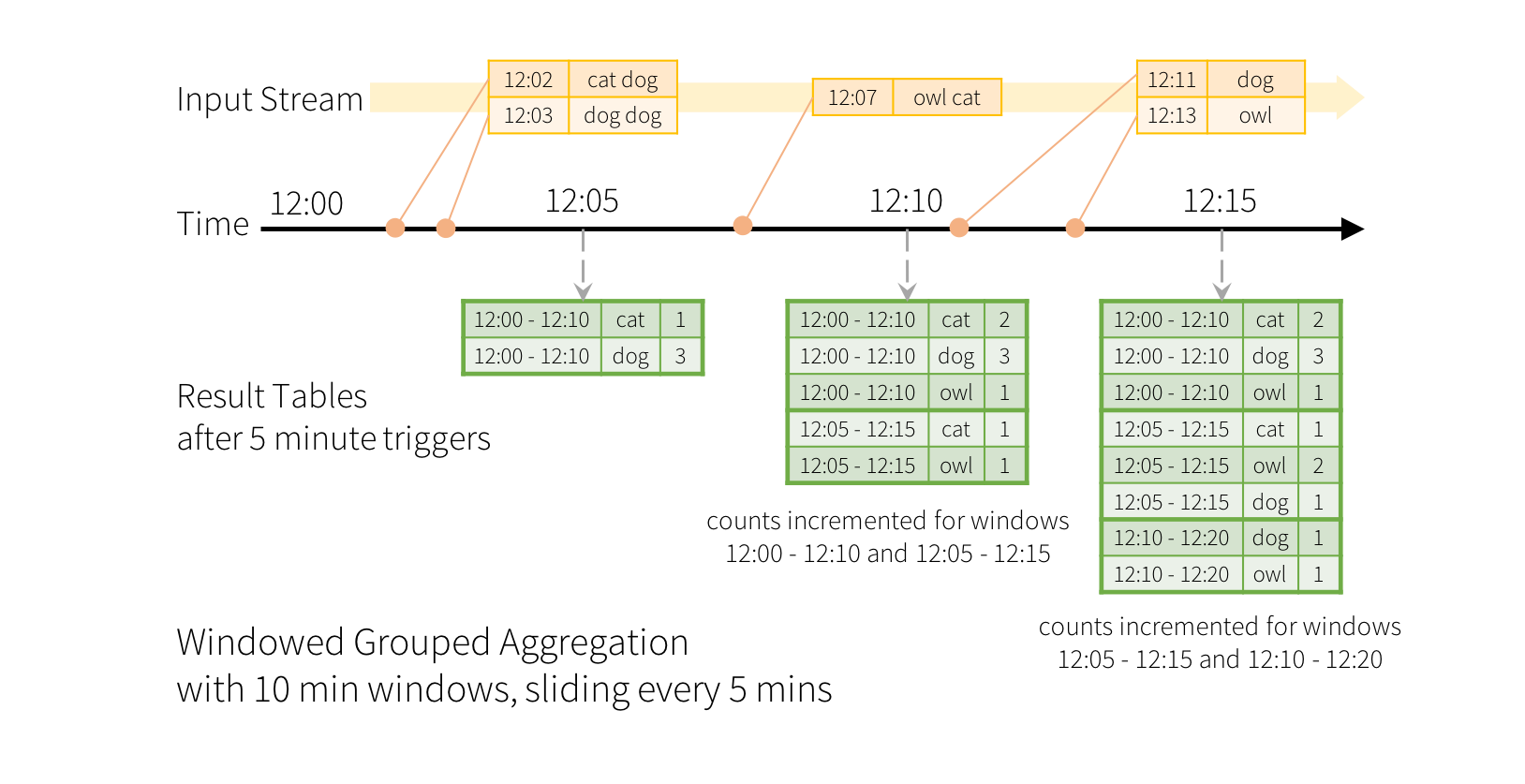
Imagine our quick example is modified and the stream now contains lines along with the time when the line was generated. Instead of running word counts, we want to count words within 10 minute windows, updating every 5 minutes. That is, word counts in words received between 10 minute windows 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20, etc. Note that 12:00 - 12:10 means data that arrived after 12:00 but before 12:10. Now, consider a word that was received at 12:07. This word should increment the counts corresponding to two windows 12:00 - 12:10 and 12:05 - 12:15. So the counts will be indexed by both, the grouping key (i.e. the word) and the window (can be calculated from the event-time).
The result tables would look something like the following.
`Furthermore, this model naturally handles data that has arrived later than expected based on its event-time. Since Spark is updating the Result Table, it has full control over updating old aggregates when there is late data, as well as cleaning up old aggregates to limit the size of intermediate state data. Since Spark 2.1, we have support for watermarking which allows the user to specify the threshold of late data, and allows the engine to accordingly clean up old state. These are explained later in more detail in the Window Operations section.
>> 기본적으로 늦은 data 들에 대해서 처리를 하지만, Spark 는 늦은데이타에서 업데이트를 지속하기위해서 old value 를 컨트롤한다. 뿐만아니라 cleaning up 도한다.
2.1 에서부터는 watermarking 을 제공하여 늦은데이타를 날릴 수 있는 Threshold 값을 조절 할 수 있다.
Now consider what happens if one of the events arrives late to the application. For example, say, a word generated at 12:04 (i.e. event time) could be received by the application at 12:11. The application should use the time 12:04 instead of 12:11 to update the older counts for the window 12:00 - 12:10. This occurs naturally in our window-based grouping – Structured Streaming can maintain the intermediate state for partial aggregates for a long period of time such that late data can update aggregates of old windows correctly, as illustrated below.z`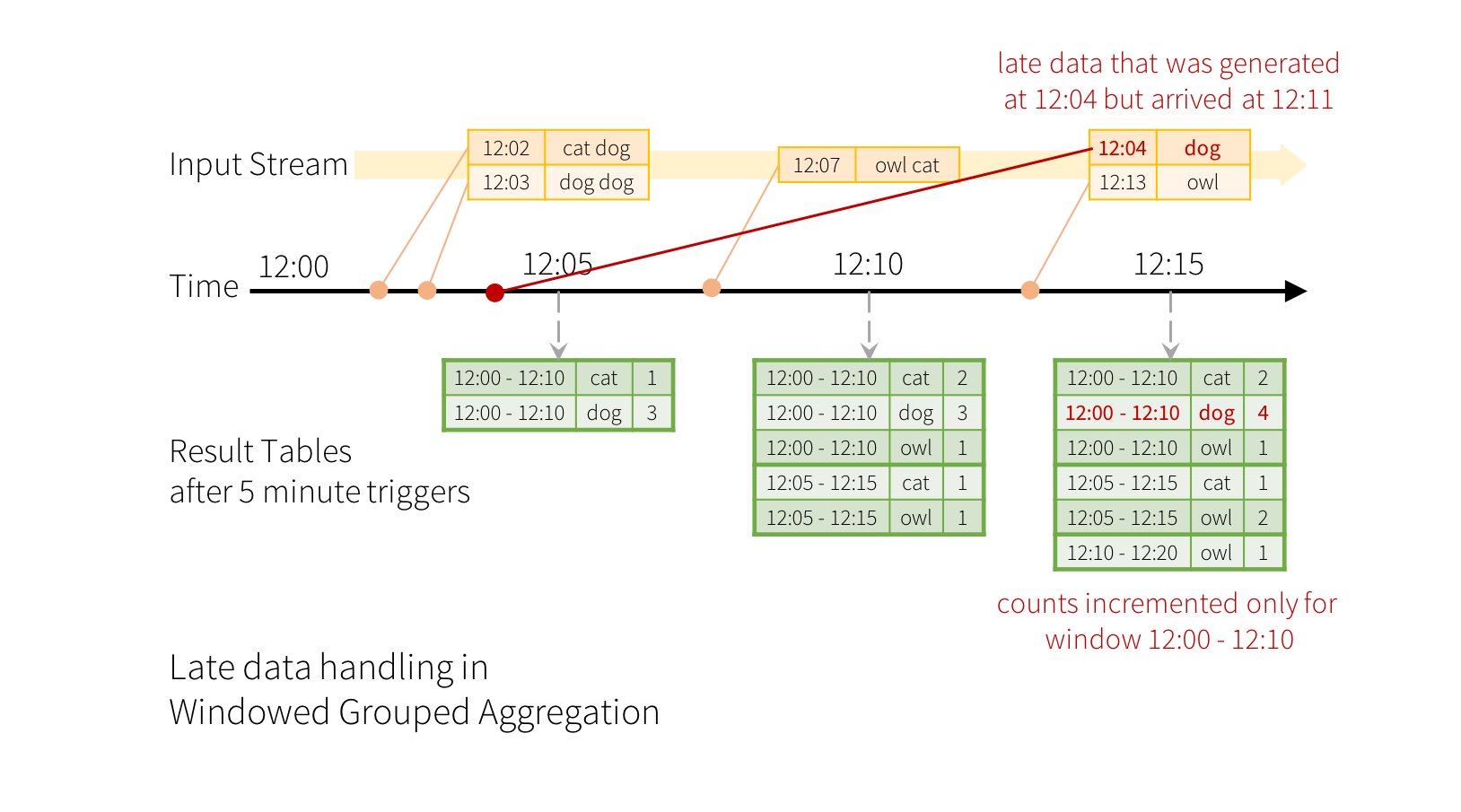
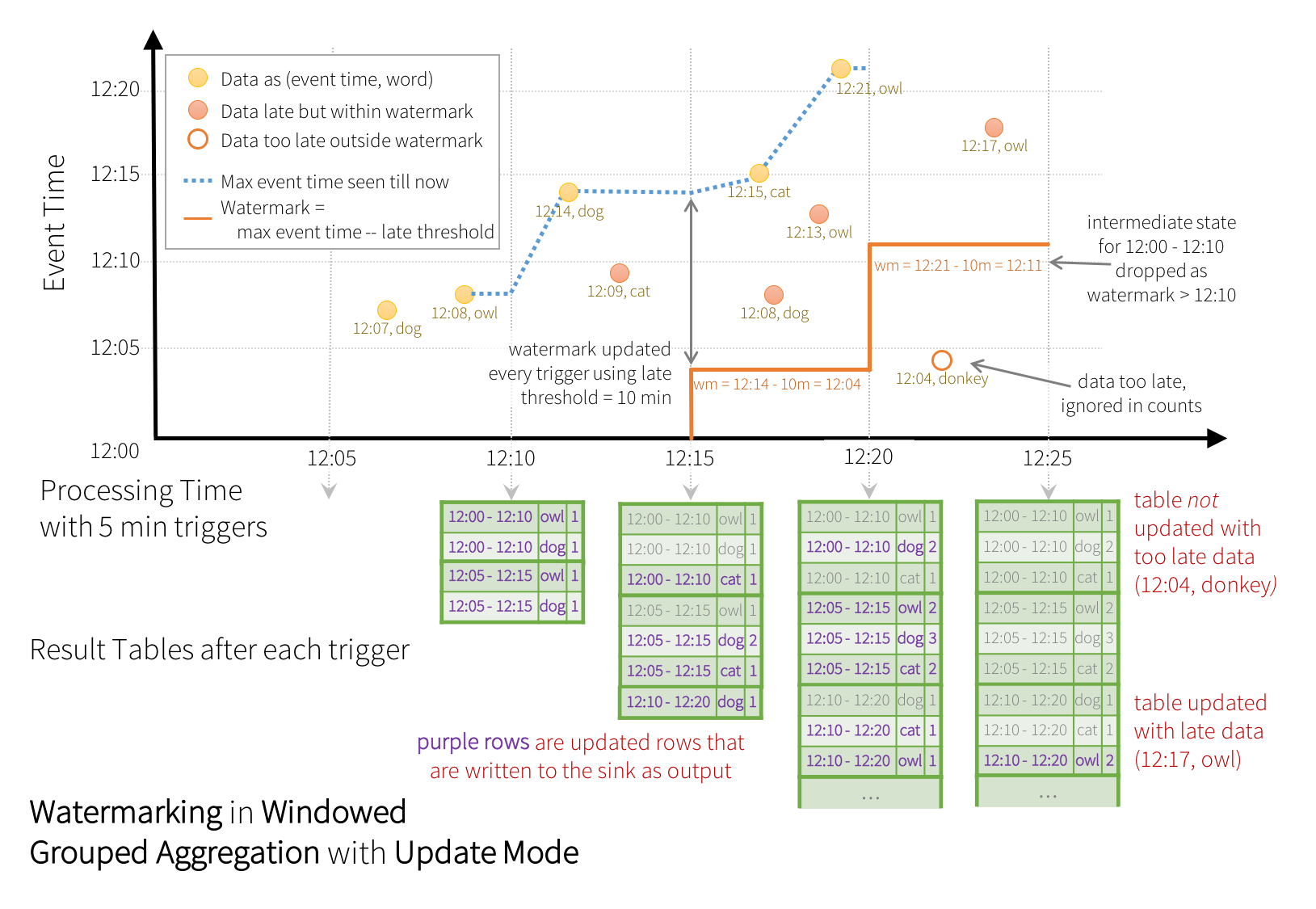
However, to run this query for days, it’s necessary for the system to bound the amount of intermediate in-memory state it accumulates. This means the system needs to know when an old aggregate can be dropped from the in-memory state because the application is not going to receive late data for that aggregate any more. To enable this, in Spark 2.1, we have introduced watermarking, which lets the engine automatically track the current event time in the data and attempt to clean up old state accordingly. You can define the watermark of a query by specifying the event time column and the threshold on how late the data is expected to be in terms of event time. For a specific window starting at time T, the engine will maintain state and allow late data to update the state until (max event time seen by the engine - late threshold > T). In other words, late data within the threshold will be aggregated, but data later than the threshold will start getting dropped (see later in the section for the exact guarantees). Let’s understand this with an example. We can easily define watermarking on the previous example using withWatermark() as shown below.
>>하지만 이것을 일단위로 돌리려면, state data 를 memory 에 들어야하고, 블라블라~ water marking 써야하고 > 이것이 지속적인 성능을 향상
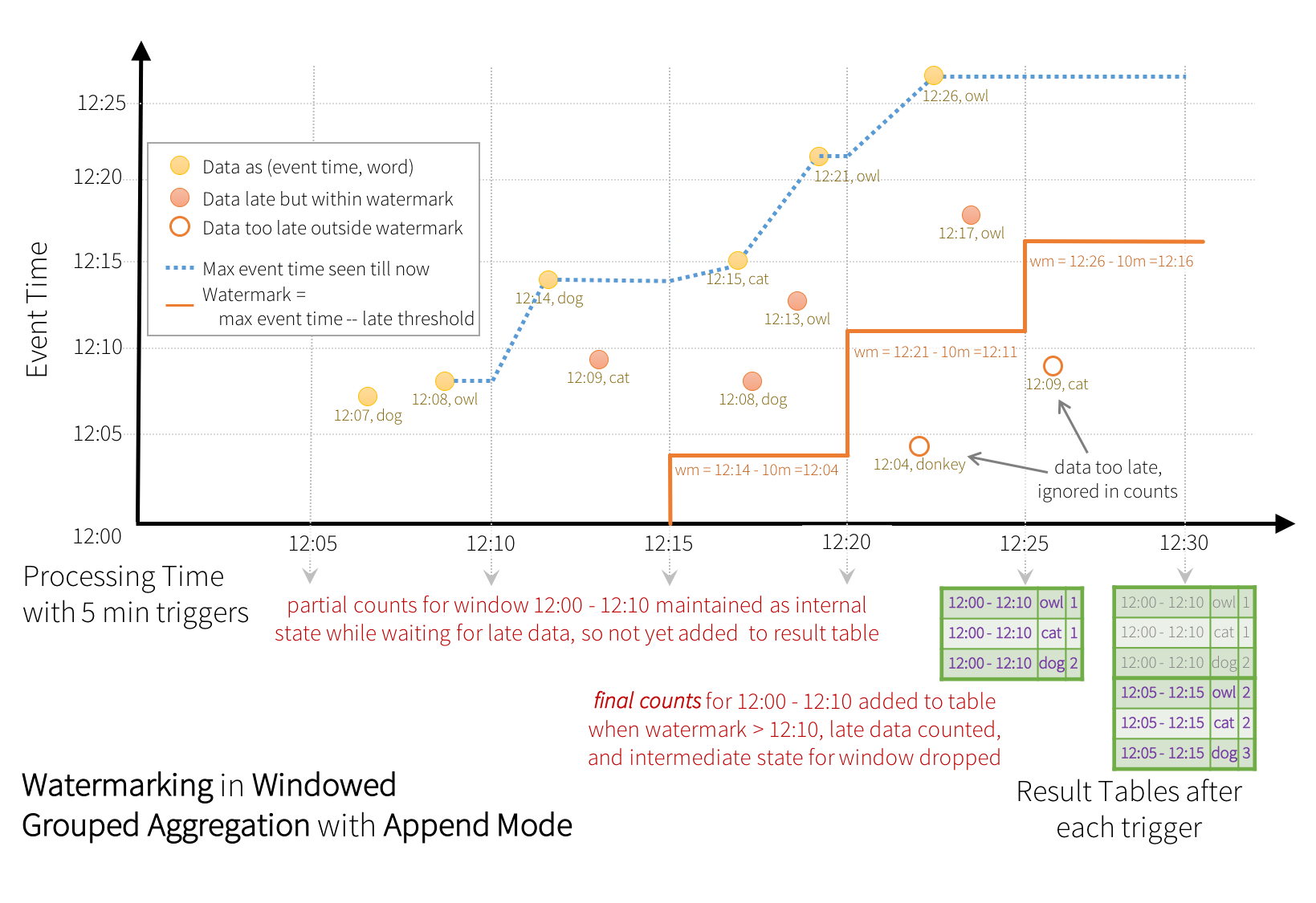
Similar to the Update Mode earlier, the engine maintains intermediate counts for each window. However, the partial counts are not updated to the Result Table and not written to sink. The engine waits for “10 mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window 12:00 - 12:10 is appended to the Result Table only after the watermark is updated to 12:11.
>> Append mode 의경우 watermark 의 유효기간까지 data 를 유지하고, 유효기간이 완료되면 추가된 row 들만 append 하게된다.
watermarking을 하기 위해선 아래조건이 만족 필요
Output mode must be Append or Update. Complete mode requires all aggregate data to be preserved, and hence cannot use watermarking to drop intermediate state. See the Output Modes section for detailed explanation of the semantics of each output mode.
The aggregation must have either the event-time column, or a window on the event-time column.
withWatermark must be called on the same column as the timestamp column used in the aggregate. For example, df.withWatermark("time", "1 min").groupBy("time2").count() is invalid in Append output mode, as watermark is defined on a different column from the aggregation column.
withWatermark must be called before the aggregation for the watermark details to be used. For example, df.groupBy("time").count().withWatermark("time", "1 min") is invalid in Append output mode.
A watermark delay (set with withWatermark) of “2 hours” guarantees that the engine will never drop any data that is less than 2 hours delayed. In other words, any data less than 2 hours behind (in terms of event-time) the latest data processed till then is guaranteed to be aggregated.
However, the guarantee is strict only in one direction. Data delayed by more than 2 hours is not guaranteed to be dropped; it may or may not get aggregated. More delayed is the data, less likely is the engine going to process it.
| Spark Struct Streaming - joins (0) | 2018.11.20 |
|---|---|
| Spark Struct Streaming - other operations (0) | 2018.11.20 |
| Spark Struct Streaming - intro (0) | 2018.11.20 |
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
| spark udf (0) | 2018.11.20 |
The key idea in Structured Streaming is to treat a live data stream as a table that is being continuously appended. This leads to a new stream processing model that is very similar to a batch processing model. You will express your streaming computation as standard batch-like query as on a static table, and Spark runs it as an incremental query on the unbounded input table. Let’s understand this model in more detail.
> Struct Streaming 의 idea 는 연속된 append 구조이다. 너는 스트리밍 계산을 노말한 batch query 형태로 계산 할 수 있을 것이다.
Consider the input data stream as the “Input Table”. Every data item that is arriving on the stream is like a new row being appended to the Input Table.
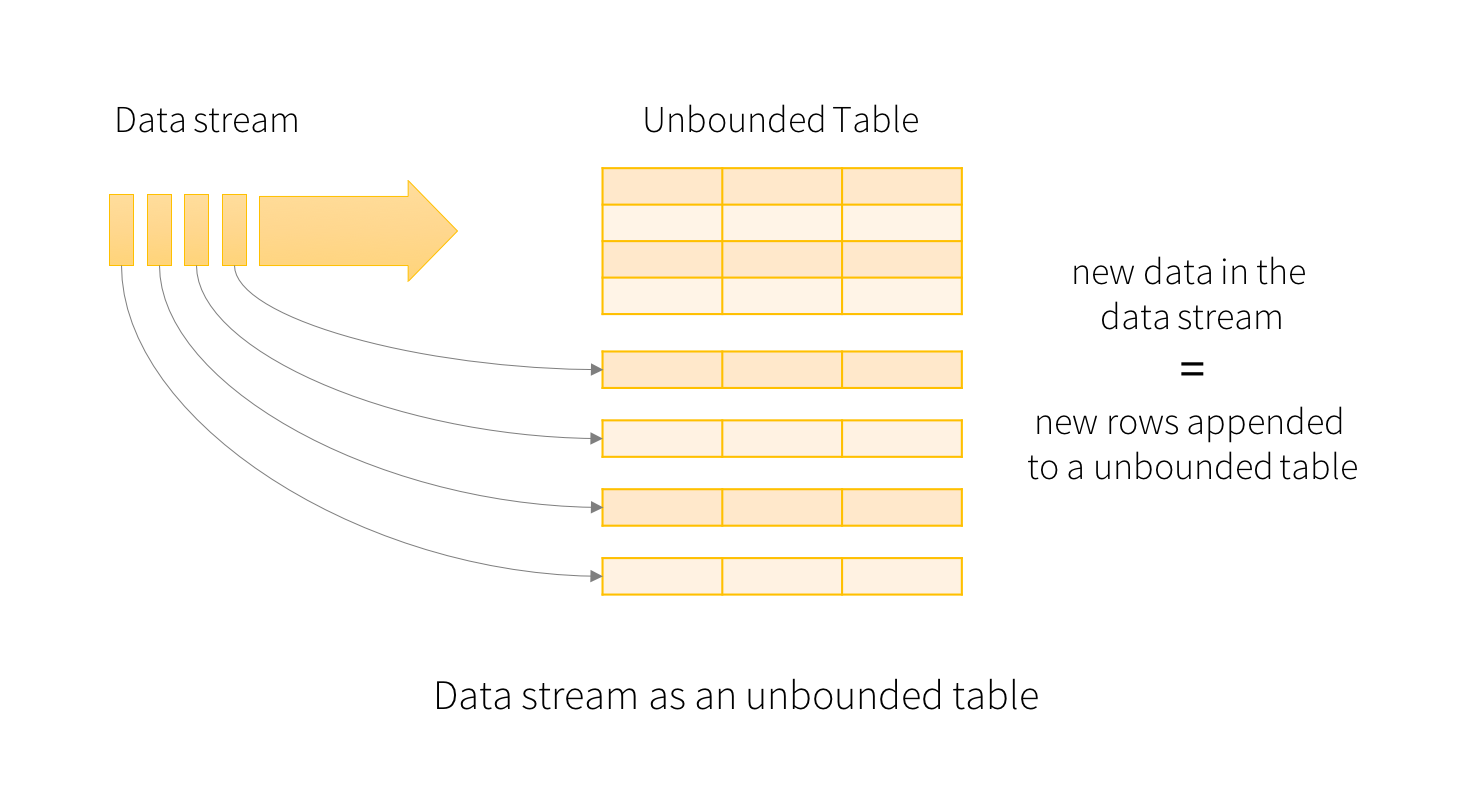
A query on the input will generate the “Result Table”. Every trigger interval (say, every 1 second), new rows get appended to the Input Table, which eventually updates the Result Table. Whenever the result table gets updated, we would want to write the changed result rows to an external sink.
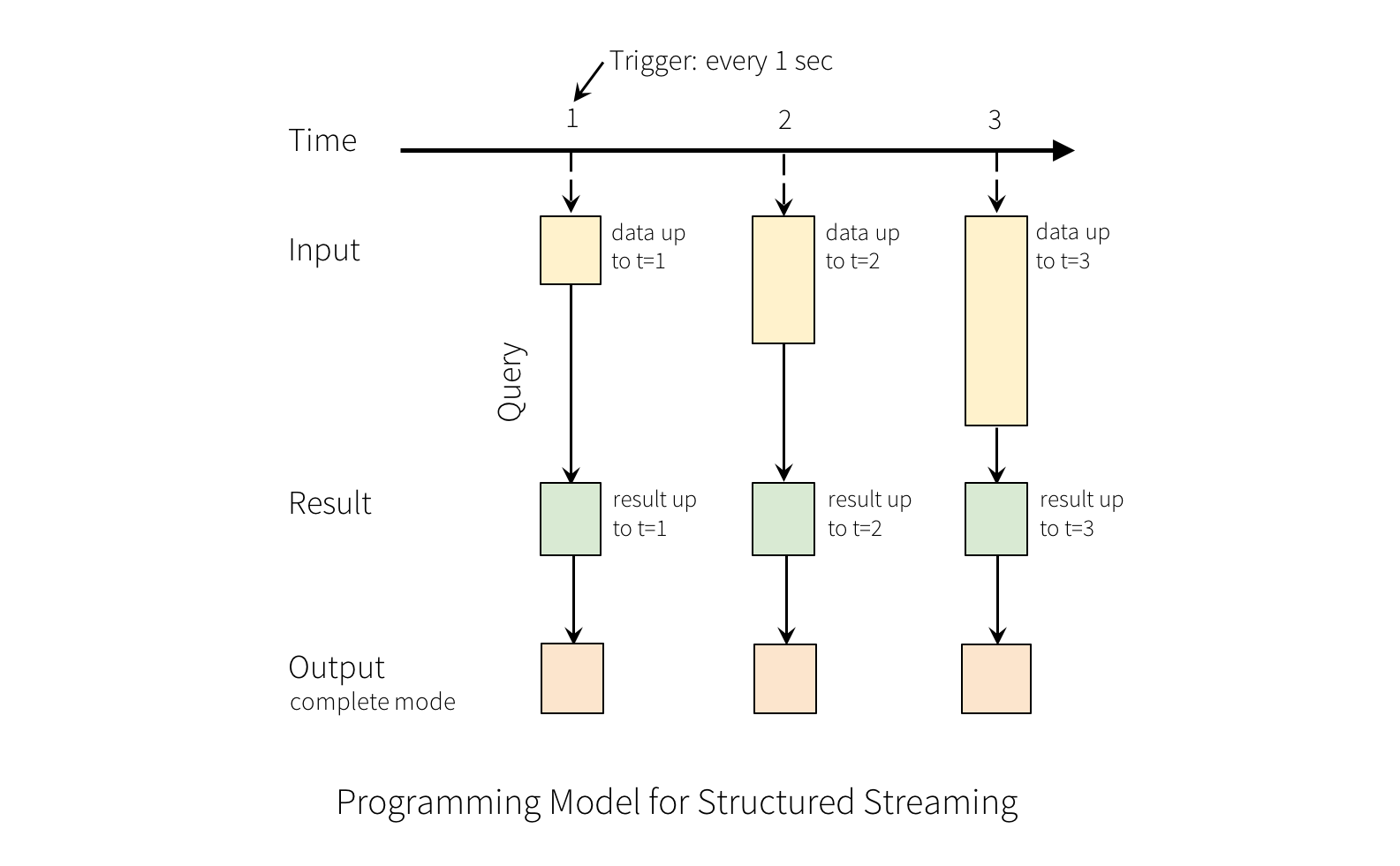
The “Output” is defined as what gets written out to the external storage. The output can be defined in a different mode:
Complete Mode - The entire updated Result Table will be written to the external storage. It is up to the storage connector to decide how to handle writing of the entire table.
Append Mode - Only the new rows appended in the Result Table since the last trigger will be written to the external storage. This is applicable only on the queries where existing rows in the Result Table are not expected to change.
Update Mode - Only the rows that were updated in the Result Table since the last trigger will be written to the external storage (available since Spark 2.1.1). Note that this is different from the Complete Mode in that this mode only outputs the rows that have changed since the last trigger. If the query doesn’t contain aggregations, it will be equivalent to Append mode.
Note that each mode is applicable on certain types of queries. This is discussed in detail later.
>> output mode 는 Complete mode / Append mode / Update 모드 3가지 가 있다.
Complete Mode 는 updated 된 Result Table 이 만들어졌을때졌을때, 외부 저장소에 출력된다.
Append Mode 는 새로운 Rows 들만 Trigger 에 의해 외부저장소에 출력 된다.
Update Mode 란 새롭거나 수정된 Rows 들만 Trigger 에 의해 외부 저장소에 출력 된다. Completed 모드와 다른점은 만약 query 가 Aggregation 을 포함하지 않으면, 이것은 Append Mode 와 똑같이 똑같이 동작한다. (Complete 모드보다 빠를것으로 예상된다.)
To illustrate the use of this model, let’s understand the model in context of the Quick Example above. The first lines DataFrame is the input table, and the final wordCounts DataFrame is the result table. Note that the query on streaming lines DataFrame to generate wordCounts is exactly the same as it would be a static DataFrame. However, when this query is started, Spark will continuously check for new data from the socket connection. If there is new data, Spark will run an “incremental” query that combines the previous running counts with the new data to compute updated counts, as shown below.
>> 구현하자면 아래와같이 구현한다.
val query = wordCounts.writeStream.outputMode("complete") or .outputMode("append") or .outputMode("update") >> 기존 SQL 과 똑같이 구현하는데, Spark 가 연속적으로 새로운 data 을 체킹한다. (socket 기반) 만약 새로운 Data 가 있으면 Spark 는 증가분에대해서 Query 를 날리게 되고 이전에 돌린 Running count 과 combine 하게 된다. (아래 그림 설명)
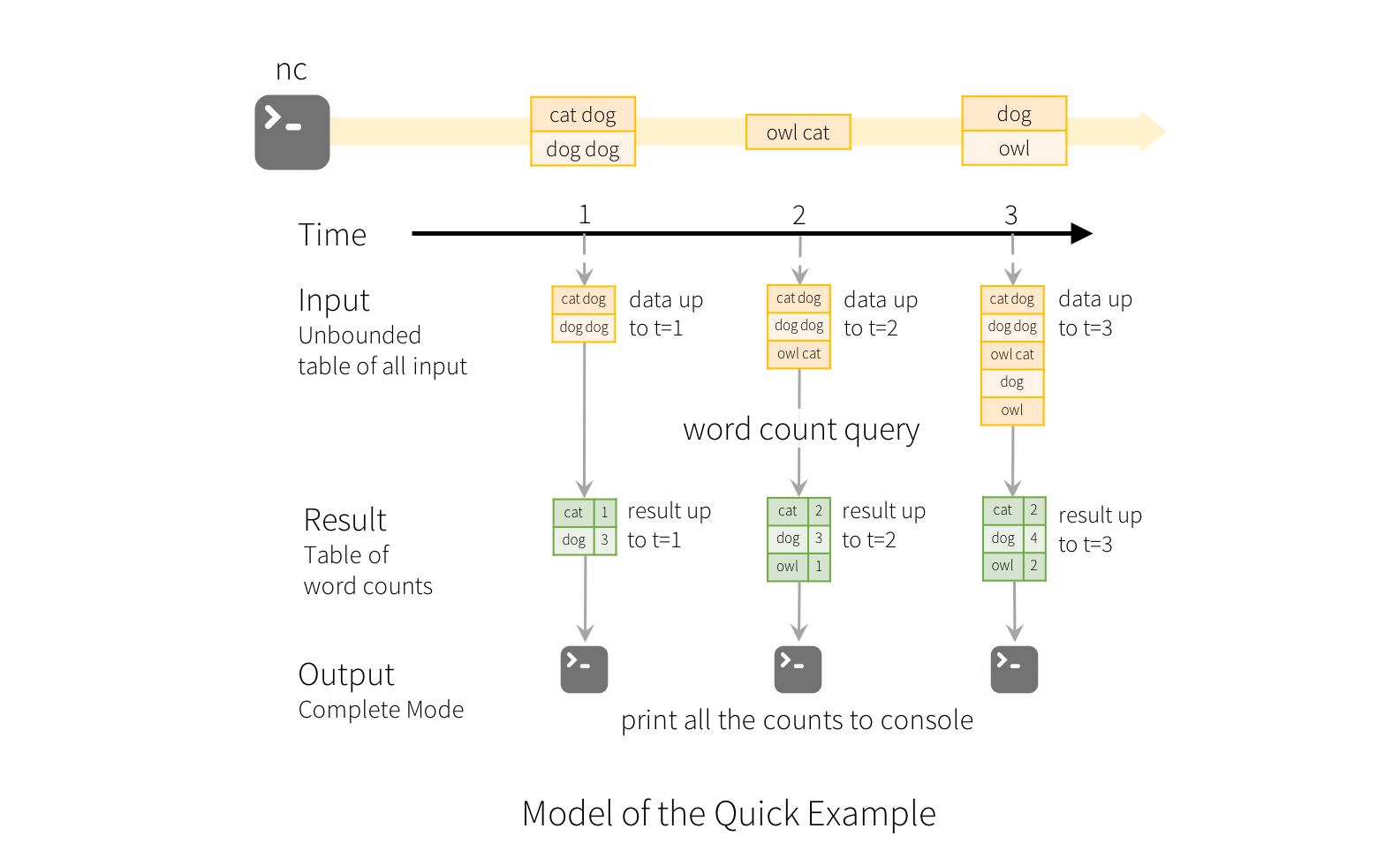
Note that Structured Streaming does not materialize the entire table. It reads the latest available data from the streaming data source, processes it incrementally to update the result, and then discards the source data. It only keeps around the minimal intermediate state data as required to update the result
>> % Struct Streaming 은 전체 Table 을 구체화 하지 않는다. 그것은 가장 마지막 사용가느한 data 를 읽고 점진적으로 Result 를 update하는 구조이다.
그리고 원본 source data 는 지우게된다. 이것은 가능한 가장 작은 data 를 유지하는데 그것을 state Data 라한다. Result 를 업데이트하기위한 것이 state Data 이기도 하다.
Most of the common operations on DataFrame/Dataset are supported for streaming. The few operations that are not supported are discussed laterin this section.
>> 기본적인 select 등의 Query 를 아래와 같이 지원한다. 다만 몇 몇개는 지원하지 않는다.
By default, Structured Streaming from file based sources requires you to specify the schema, rather than rely on Spark to infer it automatically. This restriction ensures a consistent schema will be used for the streaming query, even in the case of failures. For ad-hoc use cases, you can reenable schema inference by setting spark.sql.streaming.schemaInference to true.
Partition discovery does occur when subdirectories that are named /key=value/ are present and listing will automatically recurse into these directories. If these columns appear in the user provided schema, they will be filled in by Spark based on the path of the file being read. The directories that make up the partitioning scheme must be present when the query starts and must remain static. For example, it is okay to add /data/year=2016/ when /data/year=2015/ was present, but it is invalid to change the partitioning column (i.e. by creating the directory /data/date=2016-04-17/).
>> default 로 Struct Streaming 은 input schema 를 제시하여 입력 받도록 한다. (CSV 의 경우 지원하는데 JSON 은?? kafka 는? )
Basic Operation (like dataframe)
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API
| Spark Struct Streaming - other operations (0) | 2018.11.20 |
|---|---|
| spark struct streaming - window operation (0) | 2018.11.20 |
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
| spark udf (0) | 2018.11.20 |
| spark tuning 하기 (0) | 2018.11.20 |
Discretized Streams (DStreams) Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset (see Spark Programming Guide for more details). Each RDD in a DStream contains data from a certain interval, as shown in the following figure.
API using Datasets and DataFrames Since Spark 2.0, DataFrames and Datasets can represent static, bounded data, as well as streaming, unbounded data. Similar to static Datasets/DataFrames, you can use the common entry point SparkSession (Scala/Java/Python/R docs) to create streaming DataFrames/Datasets from streaming sources, and apply the same operations on them as static DataFrames/Datasets. If you are not familiar with Datasets/DataFrames, you are strongly advised to familiarize yourself with them using the DataFrame/Dataset Programming Guide.
해석 하자면 DStream 은 Spark 에서 기본적으로 제공하는스트림이다. source 로 부터 오는 input stream 이거나, transform 되어 제공되는 data stream 중에 하나이다.
내부적으로 DStream 은 연속적인 RDD series 로 구현 되어있다. sparkd 의 추상적인 가상화 구조이다. (RDD)
Spark - Struct Streaming 에서는 2.0에서부터는 bound 또는 unbounded Data 에서 SparkSession 으로부터 streaming 객체를 생성 할 수 있다. 이 Struct Streaming 에서는 Dataframe / dataset 의 API 를 똑같이 operation 할수있다. (실제로는, 일부는 제외)
이 밖에도 기존 D Stream 에서는 Source로 부터 입력 받을때, 기본제공 String Serializer 외에 JSON 등을 RDD 객체화하려면 별도의 Serializer 등이 필요했는데,
Spark-struct-Streaming 에서는 readStream 등을 통하여, Dataframe 객체 등을 생성한다.
| spark struct streaming - window operation (0) | 2018.11.20 |
|---|---|
| Spark Struct Streaming - intro (0) | 2018.11.20 |
| spark udf (0) | 2018.11.20 |
| spark tuning 하기 (0) | 2018.11.20 |
| transformation and actions (0) | 2018.11.20 |
Spark sql에서 사용자 정의 함수가 필요한 경우 `udf`를 이용하면 직접 함수를 정의하여 사용할 수 있다.
인자로 함수를 전달 받고 결과로 `UserDefinedFunction`을 돌려주며, 일반 컬럼 처럼 `select` 구문에서 사용이 가능
udf 함수에 작성한 함수를 인자로 전달하여 정의한다.
spark 세션의 udf()메서드를 이용하는 경우 spark가 제공하는 sql 메서드를 이용해 문자열로 작성한 쿼리에서 새로 정의함 함수를 사용 할 수 있다.
UDF는 블랙박스로 동작하기 때문에 주의해서 사용해야 한다.(https://jaceklaskowski.gitbooks.io/mastering-spark-sql/spark-sql-udfs-blackbox.html)
| Spark Struct Streaming - intro (0) | 2018.11.20 |
|---|---|
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
| spark tuning 하기 (0) | 2018.11.20 |
| transformation and actions (0) | 2018.11.20 |
| spark memory (0) | 2018.11.20 |
spark 에는 여러가지 종류의 transformation / action 등이 있다. 종류에 따라서 동작이다른데,
-map, filter : narrow transformation
-coalesce : still narrow
-groupbyKey ReducebyKey : wide transformation >> Shuffle 이 많이 일어나고, stage 가 생기게 된다.
이처럼 stage 와 shuffle 이 늘어날 수록 incur high disk & network I/O 등이 일어나 expensive 한 작업이 일어나게된다.
또는 numpatition 등에 의해 stage boundary 를 trigger 할수도 있다.
스파크를 튜닝 하는 방법은 여러가지가 있을 수 있다.

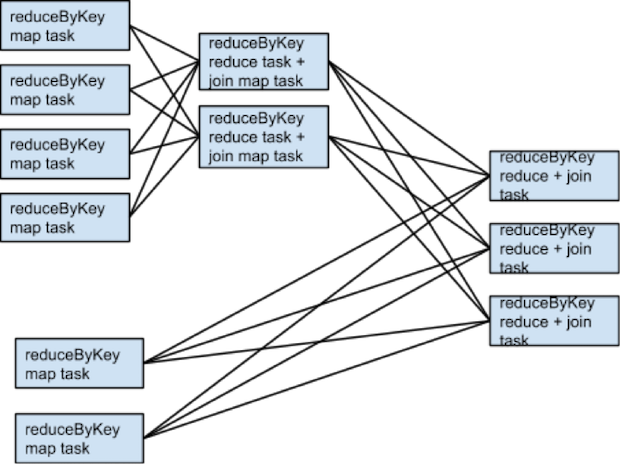
보통은 아주 많은 경우가 적은경우보다는 좋다고 한다.
7. Reduce data size 이건 당연한 소리
8. 출력 format 을 Sequence 파일로 해라
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
|---|---|
| spark udf (0) | 2018.11.20 |
| transformation and actions (0) | 2018.11.20 |
| spark memory (0) | 2018.11.20 |
| join with spark (0) | 2018.11.20 |