출처 : https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_spark_tuning.html
spark 에는 여러가지 종류의 transformation / action 등이 있다. 종류에 따라서 동작이다른데,
-map, filter : narrow transformation
-coalesce : still narrow
-groupbyKey ReducebyKey : wide transformation >> Shuffle 이 많이 일어나고, stage 가 생기게 된다.
이처럼 stage 와 shuffle 이 늘어날 수록 incur high disk & network I/O 등이 일어나 expensive 한 작업이 일어나게된다.
또는 numpatition 등에 의해 stage boundary 를 trigger 할수도 있다.
스파크를 튜닝 하는 방법은 여러가지가 있을 수 있다.
- chooosing Optimal transformatons
a. map + reducebyKey <<< aggregateByKey
b. join <<< cogroup (if already grouped by key)
후자가 더빠르다. - Shuffle 자체를 줄이는 방법
reduce by key 등의 transformation 은 lazy evaluation 이 일어나는데, 부모 Partition 갯수가 같게 세팅되면, 한번에 일어날 수 있음
그렇기 떄문에 ReducebyKey( XXX, numpartion = X) 에 들어가는 X 가 중요하다.
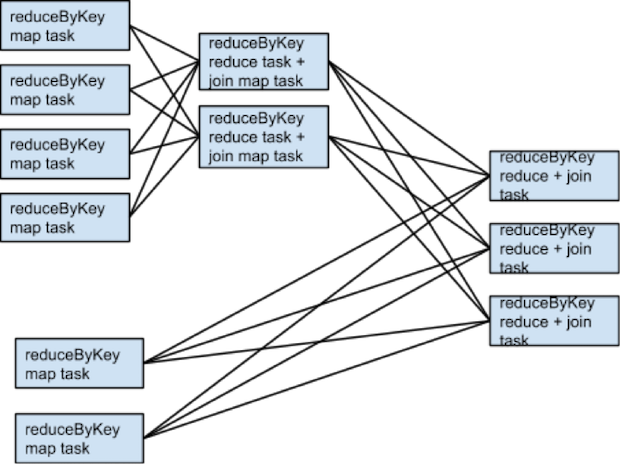
- 보통은 shuffle 을 줄이는 것의 performence가 늘어난다. 그러나 다음의 경우에는 그렇지 않다.
-inputfile 이 크고 Partition 이 늘어야 하는 경우 (shuffle 도 늘어남)
-Reduce 개수가 가 한번에 몰린경우 Tree / Tree Aggregate 등을 사용하면 shuffle 이 늘어나지만, perfomance 가 늘어날 수 있다. - secondary sort
-RepartitionAndSortWithinPartitions >> repartition + sort
전자가 shuffle machinery 를 이용하여 후자가 사용하는 sort 보다 빠르다. 이 sorting 은 join 에서도 쓰인다. - Memory tunning
-a. Yarn 을 튜닝하자
특히 Yarn.nodemanager.resouce.memory-mb / Yarn.nodemanager.resouce.cpu-vcores 를 이용하여 리소스매니저의 리소스를 확보해야한다.
-b. Executors-cores 과 executor-memory 를 실행시 옵션으로 셋팅 단, heap size 는 max(excutormemory * 0.07 ,384)
-c. AM 은 client deploy mode 와 cluster deploy mode 가 있는데, 전자는 1GB 1core 를 client 에서 할당하고
gnwksms --Driver 옵션을 이용하여 따로 설정에 유의
-d. number of cores for excutor 는 5이하가 되는 것이 좋다.
-e.tiny excutor → perf 저하 - tuning num of partitions
보통 Partition 의 개수의 따르나 아래동작은 다르다.
coalesce → fewer
union → sum of its parent partitions number
cartesian → product of its parents
특히 Join Cogroup / GrouBuKey 등의 동작은 Memory 사용률이 높고 exceed 가 발생하면, DISK I/O 와 GC 등이 일어나 속도가 감소된다. (파티션별 용량 설정이 중요)
Repartitions 으로 partition 개수를 늘릴 수 있다
heuristic 한 방법으로 OPTIMAL Partition # = 전체 코어수 *3 정도 가 좋다는데 정확하지않고, spark 에서도 1.5배씩 늘려가며 찾으라는 말을 한다.
보통은 아주 많은 경우가 적은경우보다는 좋다고 한다.
7. Reduce data size 이건 당연한 소리
8. 출력 format 을 Sequence 파일로 해라
'spark,kafka,hadoop ecosystems > apache spark' 카테고리의 다른 글
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
|---|---|
| spark udf (0) | 2018.11.20 |
| transformation and actions (0) | 2018.11.20 |
| spark memory (0) | 2018.11.20 |
| join with spark (0) | 2018.11.20 |