Window Operations on Event Time
Aggregations over a sliding event-time window are straightforward with Structured Streaming and are very similar to grouped aggregations. In a grouped aggregation, aggregate values (e.g. counts) are maintained for each unique value in the user-specified grouping column. In case of window-based aggregations, aggregate values are maintained for each window the event-time of a row falls into. Let’s understand this with an illustration.
>>Aggeregation 과정은 Structured Streaming 에서 똑바르며 grouped aggregation 과 유사하다. 다만 grouped aggregation 에서는 특정컬럼을 기준으로 정리되는데 window - based aggregation 은 Event time 을기준으로 정리된다. 된다.
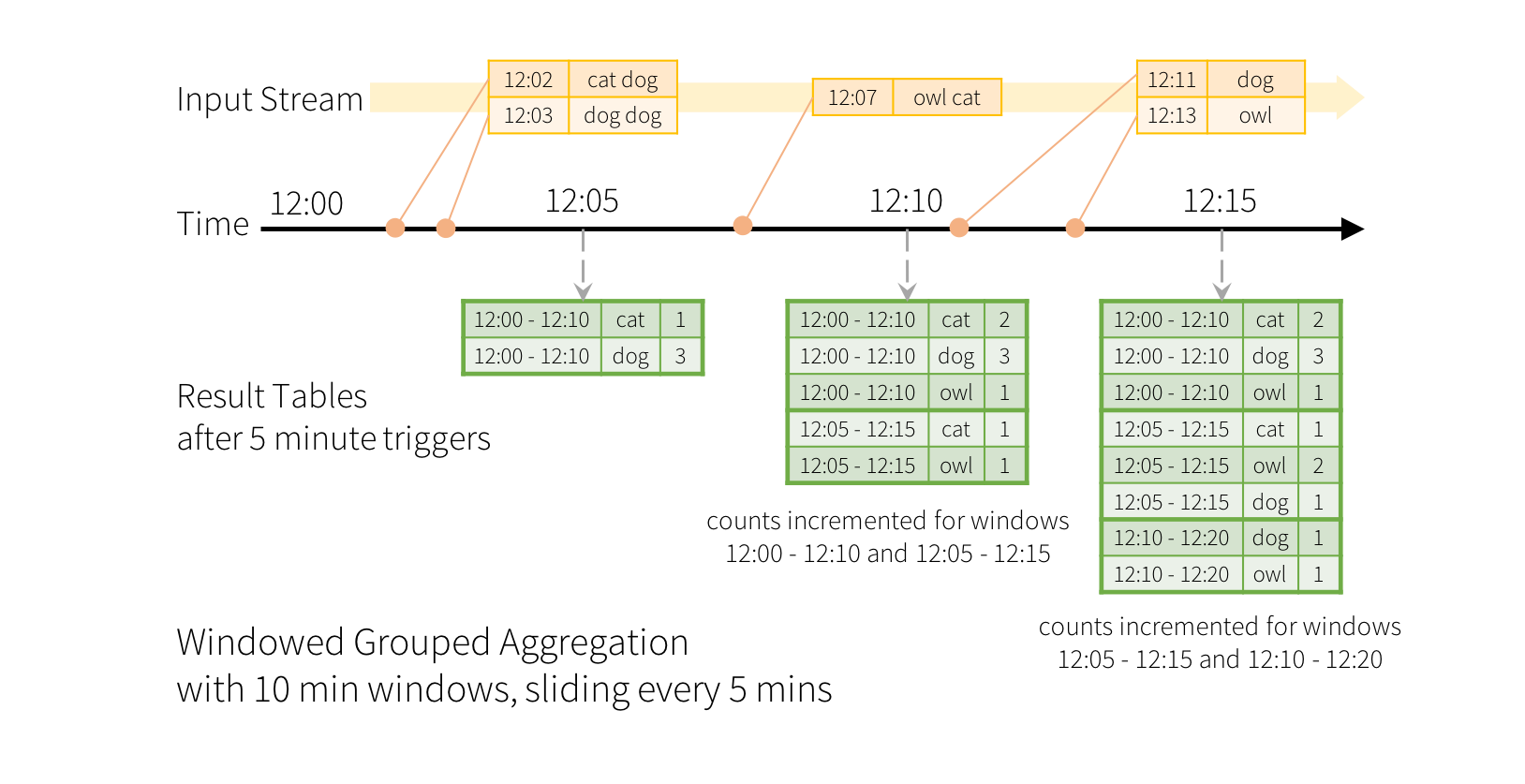
Imagine our quick example is modified and the stream now contains lines along with the time when the line was generated. Instead of running word counts, we want to count words within 10 minute windows, updating every 5 minutes. That is, word counts in words received between 10 minute windows 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20, etc. Note that 12:00 - 12:10 means data that arrived after 12:00 but before 12:10. Now, consider a word that was received at 12:07. This word should increment the counts corresponding to two windows 12:00 - 12:10 and 12:05 - 12:15. So the counts will be indexed by both, the grouping key (i.e. the word) and the window (can be calculated from the event-time).
The result tables would look something like the following.
`Furthermore, this model naturally handles data that has arrived later than expected based on its event-time. Since Spark is updating the Result Table, it has full control over updating old aggregates when there is late data, as well as cleaning up old aggregates to limit the size of intermediate state data. Since Spark 2.1, we have support for watermarking which allows the user to specify the threshold of late data, and allows the engine to accordingly clean up old state. These are explained later in more detail in the Window Operations section.
>> 기본적으로 늦은 data 들에 대해서 처리를 하지만, Spark 는 늦은데이타에서 업데이트를 지속하기위해서 old value 를 컨트롤한다. 뿐만아니라 cleaning up 도한다.
2.1 에서부터는 watermarking 을 제공하여 늦은데이타를 날릴 수 있는 Threshold 값을 조절 할 수 있다.
Now consider what happens if one of the events arrives late to the application. For example, say, a word generated at 12:04 (i.e. event time) could be received by the application at 12:11. The application should use the time 12:04 instead of 12:11 to update the older counts for the window 12:00 - 12:10. This occurs naturally in our window-based grouping – Structured Streaming can maintain the intermediate state for partial aggregates for a long period of time such that late data can update aggregates of old windows correctly, as illustrated below.z`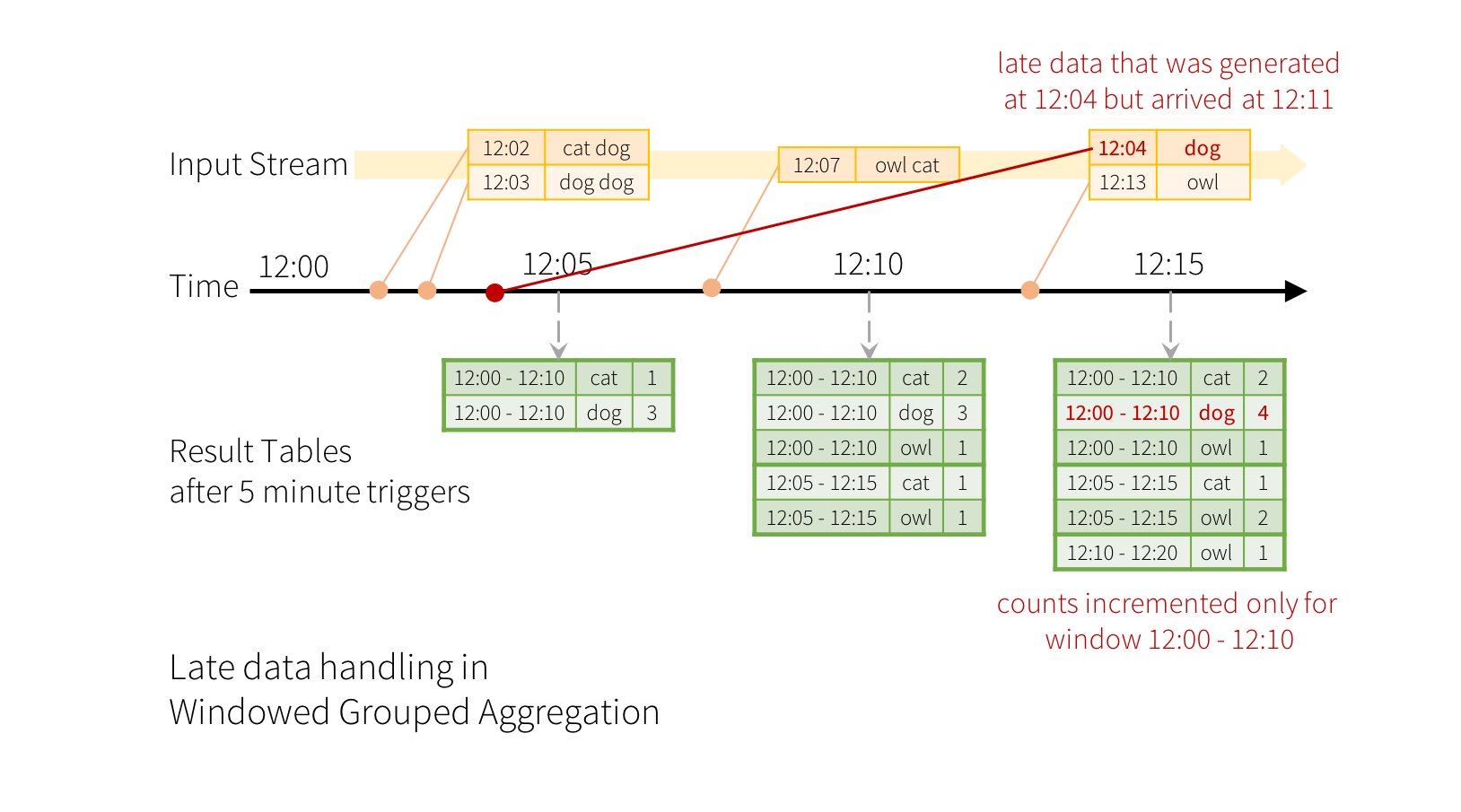
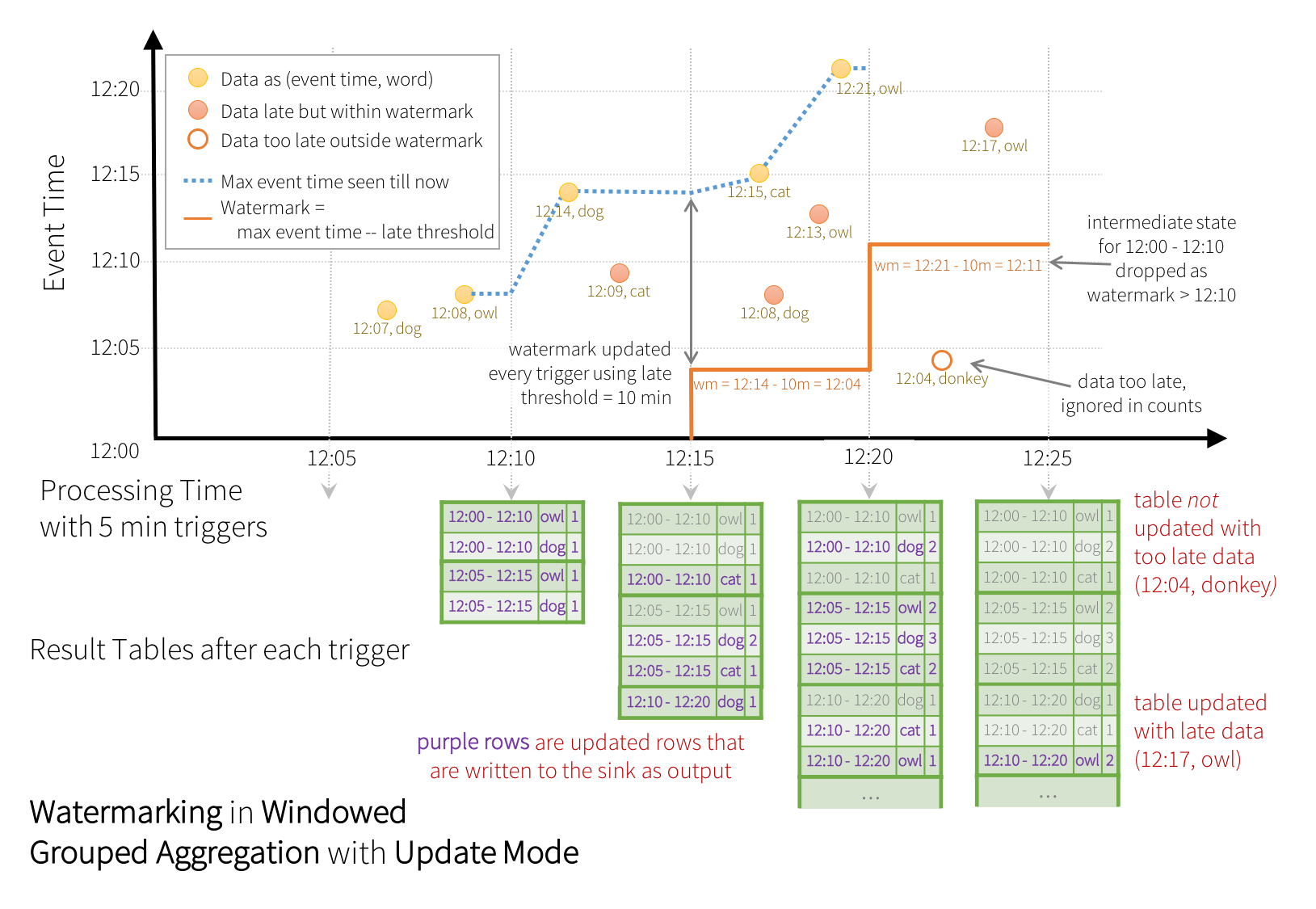
However, to run this query for days, it’s necessary for the system to bound the amount of intermediate in-memory state it accumulates. This means the system needs to know when an old aggregate can be dropped from the in-memory state because the application is not going to receive late data for that aggregate any more. To enable this, in Spark 2.1, we have introduced watermarking, which lets the engine automatically track the current event time in the data and attempt to clean up old state accordingly. You can define the watermark of a query by specifying the event time column and the threshold on how late the data is expected to be in terms of event time. For a specific window starting at time T, the engine will maintain state and allow late data to update the state until (max event time seen by the engine - late threshold > T). In other words, late data within the threshold will be aggregated, but data later than the threshold will start getting dropped (see later in the section for the exact guarantees). Let’s understand this with an example. We can easily define watermarking on the previous example using withWatermark() as shown below.
>>하지만 이것을 일단위로 돌리려면, state data 를 memory 에 들어야하고, 블라블라~ water marking 써야하고 > 이것이 지속적인 성능을 향상
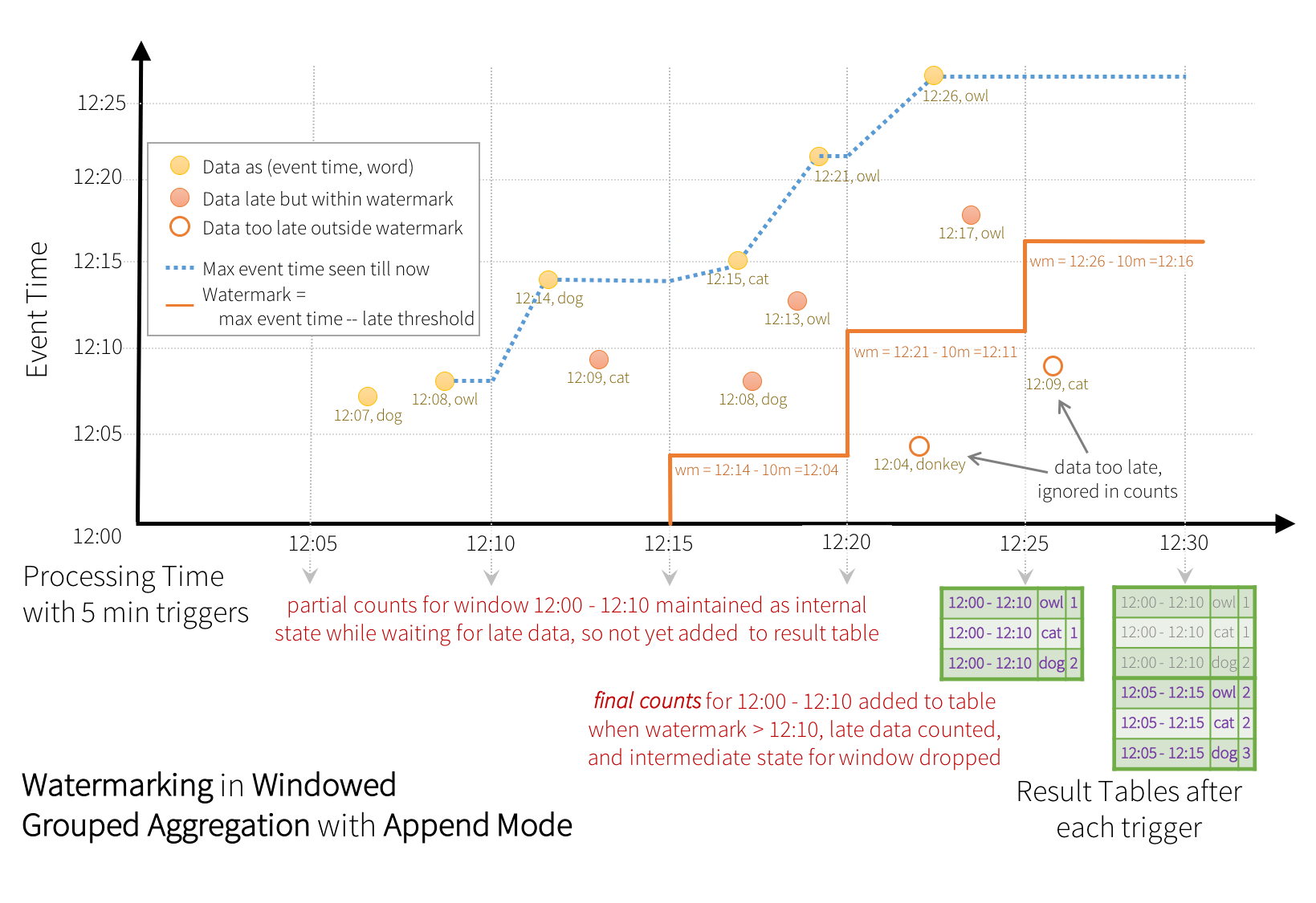
Similar to the Update Mode earlier, the engine maintains intermediate counts for each window. However, the partial counts are not updated to the Result Table and not written to sink. The engine waits for “10 mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window 12:00 - 12:10 is appended to the Result Table only after the watermark is updated to 12:11.
>> Append mode 의경우 watermark 의 유효기간까지 data 를 유지하고, 유효기간이 완료되면 추가된 row 들만 append 하게된다.
Conditions for watermarking to clean aggregation state
watermarking을 하기 위해선 아래조건이 만족 필요
Output mode must be Append or Update. Complete mode requires all aggregate data to be preserved, and hence cannot use watermarking to drop intermediate state. See the Output Modes section for detailed explanation of the semantics of each output mode.
The aggregation must have either the event-time column, or a
windowon the event-time column.withWatermarkmust be called on the same column as the timestamp column used in the aggregate. For example,df.withWatermark("time", "1 min").groupBy("time2").count()is invalid in Append output mode, as watermark is defined on a different column from the aggregation column.withWatermarkmust be called before the aggregation for the watermark details to be used. For example,df.groupBy("time").count().withWatermark("time", "1 min")is invalid in Append output mode.
Semantic Guarantees of Aggregation with Watermarking
A watermark delay (set with
withWatermark) of “2 hours” guarantees that the engine will never drop any data that is less than 2 hours delayed. In other words, any data less than 2 hours behind (in terms of event-time) the latest data processed till then is guaranteed to be aggregated.However, the guarantee is strict only in one direction. Data delayed by more than 2 hours is not guaranteed to be dropped; it may or may not get aggregated. More delayed is the data, less likely is the engine going to process it.
'spark,kafka,hadoop ecosystems > apache spark' 카테고리의 다른 글
| Spark Struct Streaming - joins (0) | 2018.11.20 |
|---|---|
| Spark Struct Streaming - other operations (0) | 2018.11.20 |
| Spark Struct Streaming - intro (0) | 2018.11.20 |
| spark D streaming vs Spark Struct Streaming (0) | 2018.11.20 |
| spark udf (0) | 2018.11.20 |