최종 목적은 단순한 이미지 분류 를 넘어서 실시간 영상에서 물체를 감지하고, 실시간 영역에서 어떤 물체인지 까지 분류 하려고 한다.
이미지 인식 분야에서 cnn 중에도 fast cnn 들에 대한 동향 리뷰를 한다.
가장 고전적인 R-CNN 은 Region Proposals(ex 색칠) 등의 알고리즘을 통해 영역을 나눠서 cnn 을 개별적으로 돌리는 방식
전체를 합쳐서 Roi(region of interests 방식 으로 폴링하는 fast-rcnn ,box sliding 방식의 faster r-cnn 등이 있다.
이 R-CNN 에서의 단점은 일단 Region Proposal 방식으로 영역을 나누고 CNN 을 돌리거나 box sliding 등의 방식을 거치는 과정중에서
시간이 많이 소요된다는 점,
이 단점을 보완하기위해서 일련의 과정을 통합한 1개의 네트워크 학습방식 (single shot Detecor) 을 사용하게된다.
대표적인 것이 yolo 와 multibox detector
yolo 는 googlenet 네트워크를 응용( 심화 ?) 한것 인데
input image - box 를 데이타로 활용하여, labeling 한뒤
학습된 이미지를 7x7 boundary box 로 나누고 각자 confidence score 과 P ( class | object) 가 학습되도록 네트워크를 설계하였다.
그 방식에 대하여 대략적으로는 이해가 가지만, 네트워크 구성에 대해서 좀 더 정확히 알기 위해서는 소스를 까봐야 될듯 하다.
R-CNN
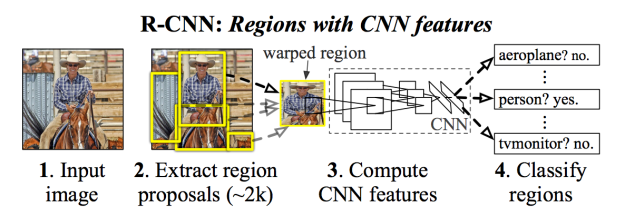
- basic model
-region proposal
-bounding box
[-selective search](http://www.cs.cornell.edu/courses/cs7670/2014sp/slides/VisionSeminar14.pdf)
Fast R-CNN

-sum up the regions and total CNN
-Region of Interest Pooling(RoIPool)
Faster R-CNN


-scoring with anchor boxes (1:1 / 1:2 / 2:1 ..etc)
YOLO(You only Look Once)
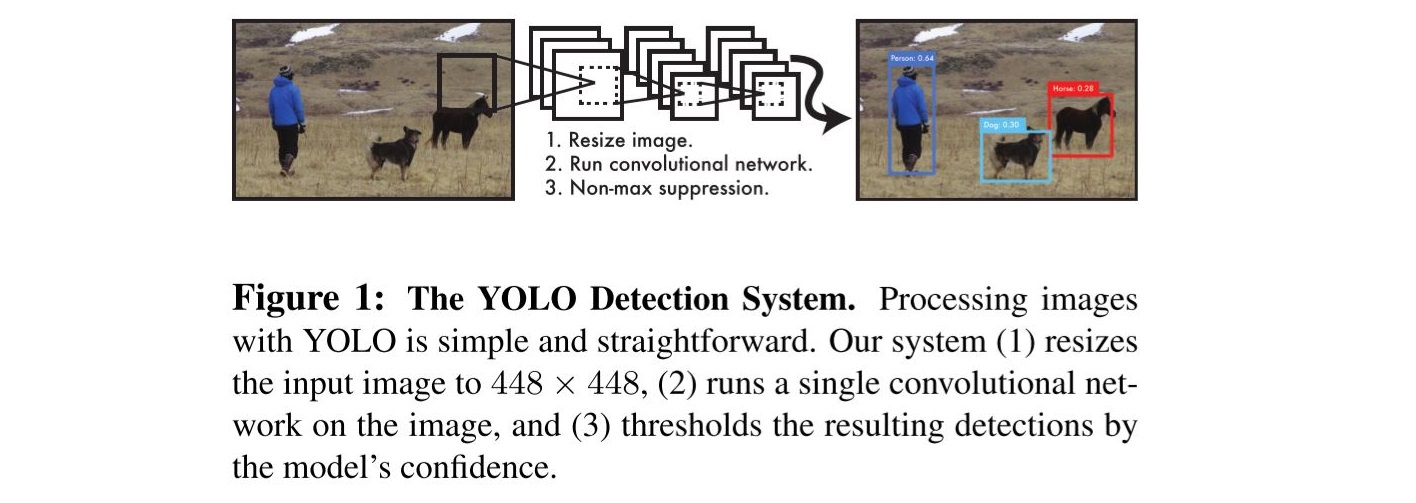
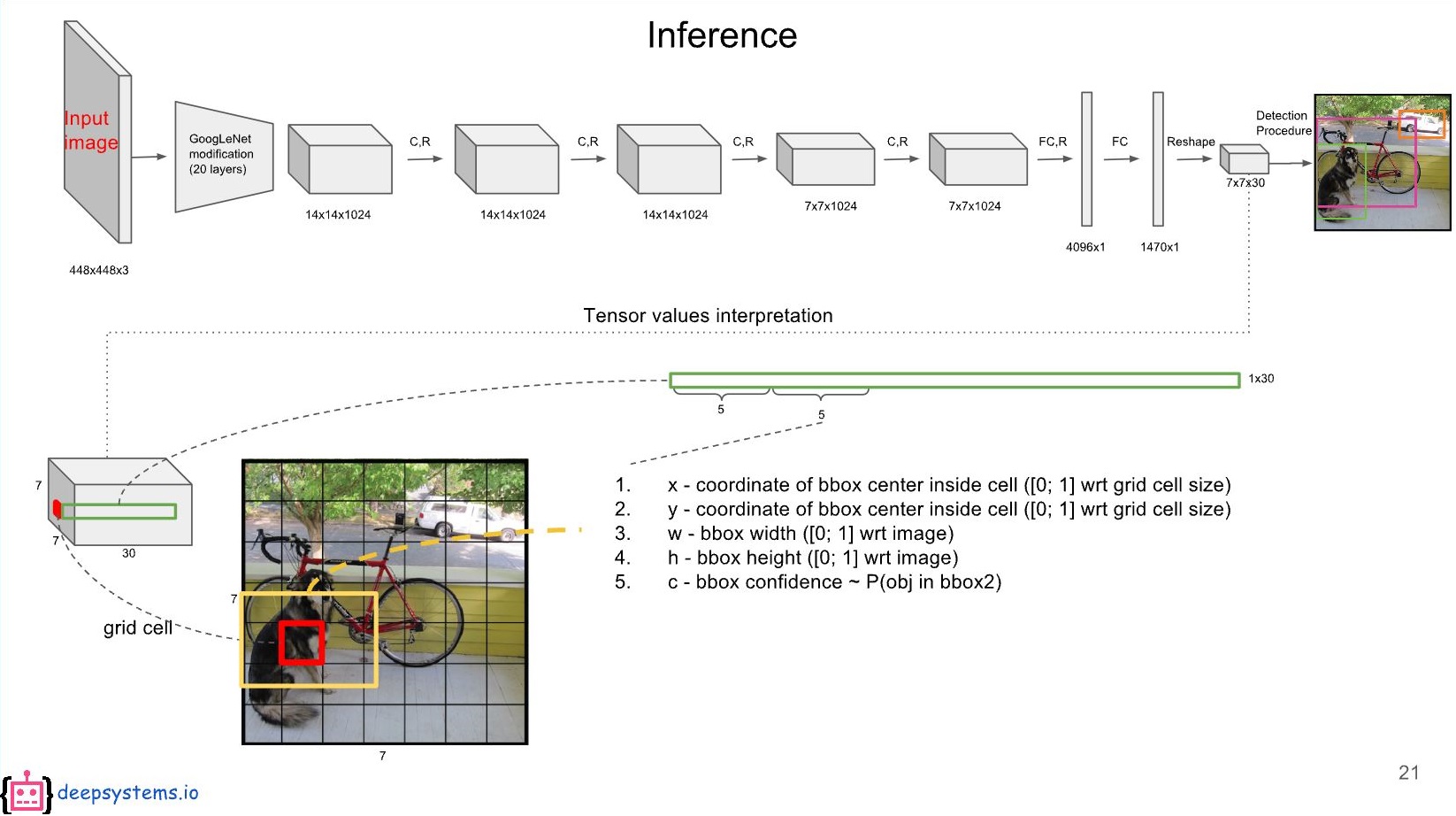
-confidence score : 0 if no object
equal to iou if there is object
-improve of googlanet
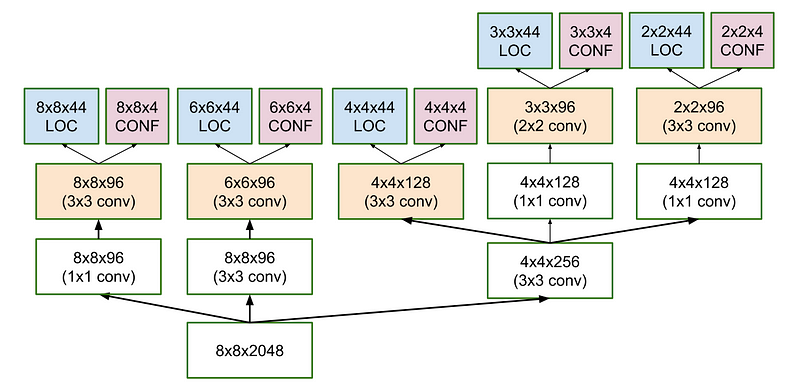
SSD - CNN Single Shot Detector

!img
{kind=link}
-improve of VGG16
-variety of feature map size
PERFORMANCE TESTS

REFERENCE
https://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
yolo paper : https://pjreddie.com/media/files/papers/yolo.pdf
ssd paper : https://arxiv.org/pdf/1512.02325.pdf
'Machine.Learning' 카테고리의 다른 글
| rtx 3080 - ubuntu 20.04 개발환경 설치기 (0) | 2021.01.22 |
|---|---|
| 머신러닝 족보 ! scikit learn algorithm cheat sheet (0) | 2019.09.04 |
| ML 환경 구축기 (e gpu 와 각종 드라이버 설치) (2) | 2019.04.16 |
| machine Learning Automation (0) | 2019.04.08 |
| tensorframes (0) | 2018.11.20 |