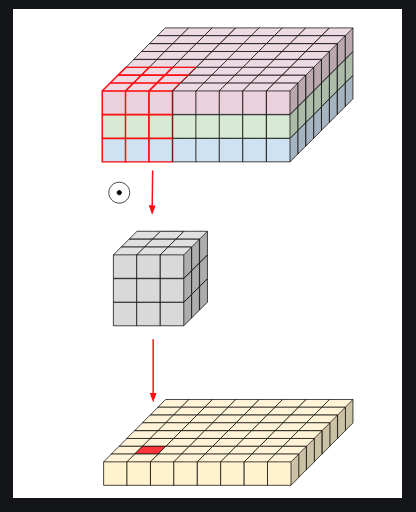
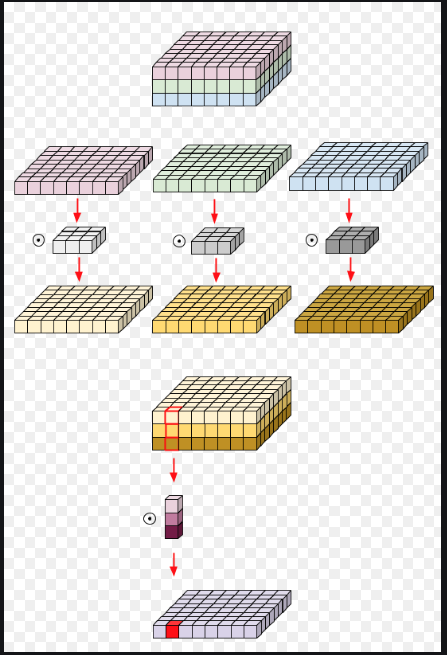
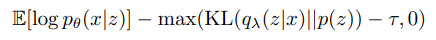3D diffusion baseline SDS에서 GAN 을 샘플링하여 학습시키고, 퀄리티를 올리기위해서 다시 diffusion model 에 넣어 랜더러를 optimize
LightFormer: Light-Oriented Global Neural Rendering in Dynamic Scene
the proposed approach focuses on the neural representation of light sources in the scene rather than the entire scene, leading to the overall better generalizability. The neural prediction is achieved by leveraging the virtual point lights and shading clues for each light, 두르뭉실하게 light 받는게아니라 light 소스로부터 representation 을 받는가보다, 논문비공
dynamic light transportation between an object and the environment. It enables interactive rendering with global illumination for dynamic scenes and achieves comparable quality 라고는 하는데, object 중심으로 light를 transfer 하는 모델 , 논문공개가안되있음, https://github.com/google/neural-light-transport?tab=readme-ov-file < 비슷한논문?
inverse rendering 에서는 lighting 을 분리하는 모델 이 존재하는데, distant 하지 않은 light 에대해서 inaccurate 가 발생한다. 그것을 줄이기위해서 Non-Distant Environment Emitter 을 설계함, inverse rendering 배경지식이 없어서 조금햇갈림
provisional image 을 만들고 target lighing 을 이용해 foreground 를 relighting relighihging 하는 모델을 controlnet 으로 학습시킨듯, encode the effect of the target lighting on each pixel’s outgoing radiance using radiance hints. 논문은 무성의함ㅋㅋ lighting contronet 이 prmpt 로 재질도 컨트롤 하는듯
IntrinsicDiffusion: Joint Intrinsic Layers From Latent Diffusion Model
back+front 를 분리하는 layer diffusion의 후속논문(?), regulating the added transparency as a latent offset “latent transparency” 를 학습했다는듯, “latent transparency” 는 alpha channel 값을 latent 의 메니폴드로 encode 한다( 기존학습모델에 같이 사용가능)
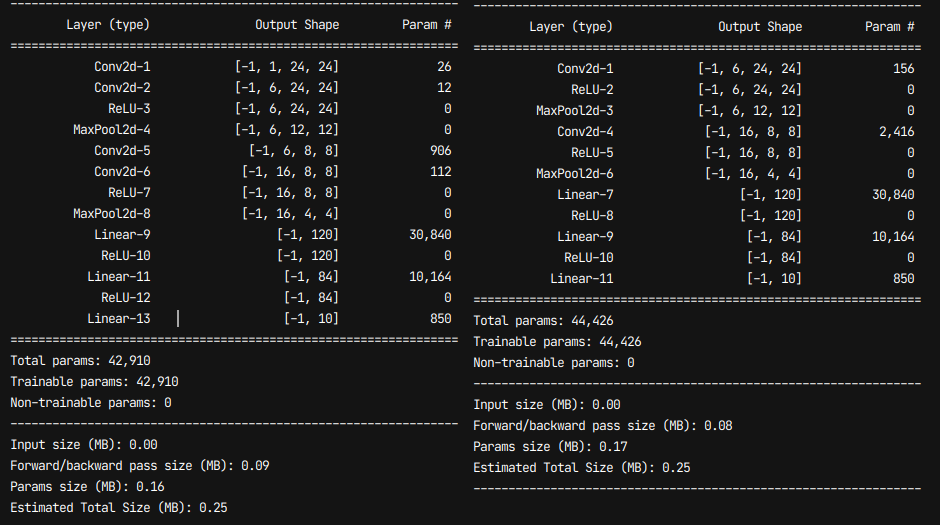
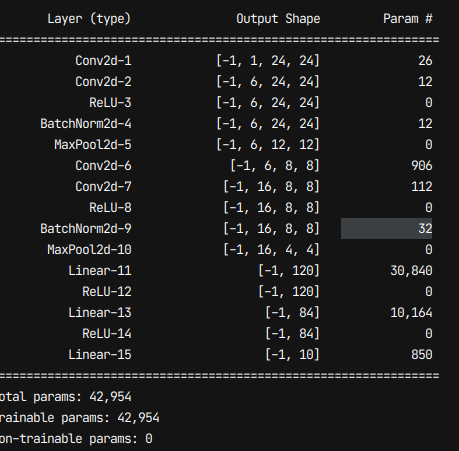
3. pytorch 설치 (2.0.1) with cuda 11.7 torch 버전은 크게 영향은 없는듯
4. cub 환경 설치 cuda\inculde\thrust\cuda\version.h
에 맨 윗출을 추가해놓는다. (#define THRUST_IGNORE_CUB_VERSION_CHECK true)
cuda 11.7 의 경우 cub 11.5 를 포함시켜놓았는데, 이 cub 사용시 pytorch3d 빌드시 문제가된다.
#define THRUST_IGNORE_CUB_VERSION_CHECK true
#ifndef THRUST_IGNORE_CUB_VERSION_CHECK
#include <thrust/version.h>
#if THRUST_VERSION != CUB_VERSION
#error The version of CUB in your include path is not compatible with this release of Thrust. CUB is now included in the CUDA Toolkit, so you no longer need to use your own checkout of CUB. Define THRUST_IGNORE_CUB_VERSION_CHECK to ignore this.
#endif
// Make sure the CUB namespace has been declared using the modern macros:
CUB_NAMESPACE_BEGIN
CUB_NAMESPACE_END
5.내장된 cub 11.5 를 11.7로 바꾸는 작업을 할것이다.
방법은 2가지가 있는데, cuda 설치경로에 cub 11.7 을 덮어씌우는 방법과 cub_home 환경변수 등록후
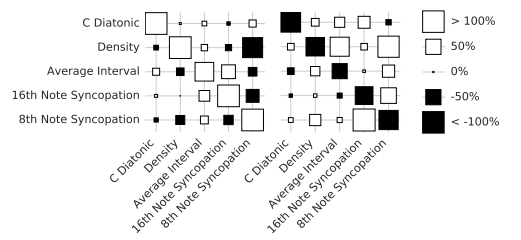
오늘 리뷰할 논문은 LSTM 구조를 VAE 로 활용해서 Music data Reconstruction 을 시도한 논문을 설명하겠습니다.
2.Back ground
2-1.Recap VAE
fig.1fig.2
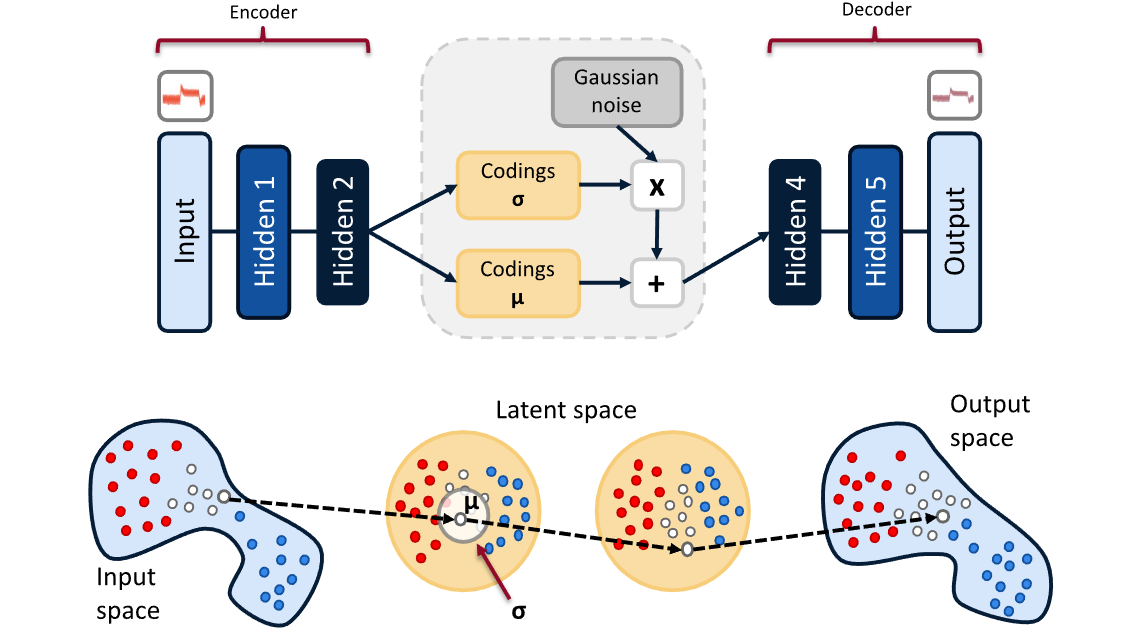
VAE 에대해서 잘 설명해 놓은 그림이다.
기존 AutoEncoder 는 Encoder 와 Decorder 로 이루어져있는데 잠재공간에 대해서 별다른 제약을 두지 않는다.
VAE 는 잠재공간을 가우시안 분포들로 latent space 를 이룰 것이라 가정하고 출발한다.
VQ-VAE, Diffusion 모델도 이와 비슷한 가정으로 출발 하는 것으로 생각하고있다.
VAE는 AE 처럼 직접적으로 latent space 를 맵핑하는 대신, 평균(뮤) 과 분산(시그마) 를 이용해 latent space 를 맵핑하려고합니다. 결과적으로 2번째 scatter plotting 된 것 과 같이, VAE 에서 맵핑된 latent 를 plotting 하면 가우시안(구형분포) 를 가지는 것을 볼 수 있다.
eq. 1
다시 첫번째 그림+수식으로 설명하자면
VAE의 목적은 Generative model 을 만드는 것인데, 일단 쉽게 생각해보면 이미지 Reconstruction 하는 것과 유사합니다.
Generative model 은 결국 P(x) 를 1로 만들자(확률분포의 총합은 1), 즉 생성된 데이타 x 의 확률분포가 원래의 x 와 같게 나올 확률을 높게 만드는 것이기 때문에 결국 log p(x) 를 크게 만들면 되는 것입니다.
왼쪽에 식은 VAE 의 구조를 이용해서 유도되는 log p(x) 의 하한 선인데,
VAE = q_lambda(z|x) (Encoder) * p_seta(x) (Decoder) 로 전개 할 수 있는데
2. Noise 를 가정하면 부드러운 latent space 분포가 만들어진다. 결국 우리가 하려는 것의 목적은 좋은 Latent space 를 만들고 그곳으로부터 sampling 하여 좋은 sample 를 얻고자 하는 목적에 부합하다.
3. 2에서 부드럽다 라는 말이 참 애매한데, 어찌보면 Overtuning 같은 것일 수도있고, 최근 Contrastive learning Yolo-R 과 같이 Represent learning 을 시도하려는 쪽에서는 이러한 Reparametrization Trick 을 이용해서 우리가 잘 알지못하는 잠재공간의 무엇인가를 모델이 알아서 학습 시키게 하려는 그런 시도라고 생각한다.
Eq.3
2-2. β- VAE
Eq4-1Eq4-2
위에 나온 Loss 에 β 가중치를 곱한다.
β<1 로 만들면 모델이 Reconstruct 에 집중 할수 있도록 한다.
EQ 4-2 같은 경우에는 KL divergence 의 타우라고 하는 Treshold 값을 주었는데, 이 값을 줌으로써,
모델은 KL 다이버전스가 충분히 낮다(인코딩이 원하는 분포 대로 되었다) 일 경우에 전체적으로 loss 에 집중하고
KL 이 높을 때는 뒤에 term 이 상대적으로 커지게 되어서 무시하려고한다.
이러한 작업은 모델로부터 더 필요한것에 집중할 수 있도록 추가적인 정보(예산)를 주는 것이라고 해석하였다.
2-3. latent space manipulation
AE 의 목적은 compact 한 Representation 을 학습하는 것이고,
그렇다는것은 data 에서 small Perturbation 이 결과적으로 Recon 된 이미지에서 비슷해야한다.
그래서 sampling 된 z1,z2 사이에 무수히많은 C_a 를 interpolation 하고, 그것들은 다시 recon 했을 때 모두 Realistic 해야한다.
특히 z 는 가우시안 분포를 따를것이라고 가정했기 때문에, Spherical interporlation (구면을 따라) 하게 된다.
이러한 생성에 대한 실험은 Attribute vectors ( 음악의 속성 vector ) 를만들어서 추가 실험을 해보았다.논문내의 (5-5)
특징 1. Encoder 의 LSTM output 중 hidden shell output h_T 를 이용해서 시그마,뮤를 예측한다.
2.Decorder RNN 에서는 잠재벡터 z 를 초기 shell 에서 initial state 로 입력 받고, decoding 한다.
3. 모델은 recon 과 동시에, KL Divergence 를 줄이는 쪽으로 계산된다.
하지만 2개의 한계점이 있다.
1. decorder 자체가 그럴싸하게 recon 은 잘하는데, z latent code 를 무시하는 경향이 있다. z 의 영향이 작아지면 KL도 작아지고 결국 autoencoder 로 서 역할을 못하게된다(?)
2. 모델이 긴 Seq 를 하나의 z space 로 Encoding 하게되므로 한계가 있다.
3. Model
Fig.4
그래서 모델은 크게 3개의 part 로 구성되어있다.
Encoder, Conductor, Decorder
input data sequence = [x1,x2....xU]
Encoder : 2 layer LSTM 구조이고, 위 Refer 한 논문 과 같이 h_t 를 이용하여 latent code 인 z 를 생성한다.
(decoder) Conductor : Two layer undirectional LSTM 구조이고, 미리 구간 별로 나눠놓은 data sequence 에 대해서 매칭되도록 [c1,c2....cU] 를 generate한다.
Decoder : 2layer lstm 구조이고, 위의 출력인 c1...cu 를 decoder 의 output 과 concat 하여 input 으로 놓고 , initial state 는 모두 z 로 setting 한다. (특이한부분?)
Decorder 에서 이러한 조작을 한이유는 1.latent z 가 RNN 의 뒤로갈수록 limit 가 있었고 CNN 이면 그런 Receptive field 를 쉽게 줄일 수 있으나, RNN 의 경우에는 이게 제한이 없어서 어렵다고 설명하고 있다. 그래서 Decoder 의 ouput sequence 가 들어가는 영향을(concat,initstate)통해서 줄였다고한다.
decoder 의 state 을 conductor 의 state 로 전달 한경우에도 실험이 더 안좋아졌다고한다. Conductor 는 그래서 혼자서 잠재공간을 decoding 하는 역할에만 집중 하게 시켰다고한다.
*Multi sound 의 분리를 위해서 Melody, drum, bass 가 섞이는 경우 othgonal dimension 을 분리하였다고한다.
4. 결과
4-1 dataset
input : wav(midi) files
2bar , 16 bar 음악에서 마디에 해당되는 듯 싶다.
2bar = 2마디 = 2U = 32T , (1마디에 16개 구간이 존재한다로해석)
16bar = 16마디 = 16U = 256T , (1마디에 16개 구간이 존재한다로해석)
output seq : 마디당 16개의 quantized 된 note 를 16개의 인터발안에서 구분지어놓은 것 같다
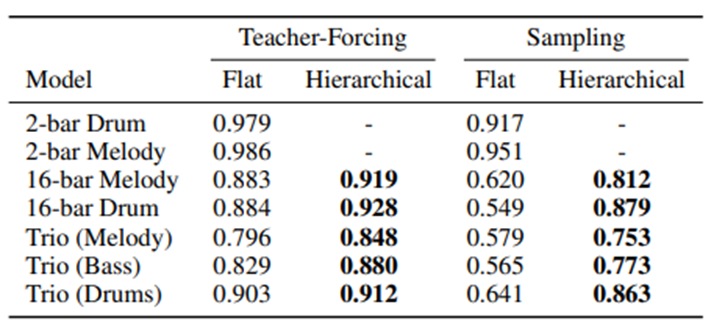
결과1. Flat 은 seq 를 한번에 넣은경우 Hierachical 은 아까와 같이 subsequence 로 놓은경우
Teacher forcing 은 GT 를 다음 output 의 input 으로 넣어 학습한경우 sampling 의 경우에는 predicted label 을 input 로 넣은경우 이다. 전체적으로 Hierachical-teacher-forcing 의 경우 더 좋은 결과가나온다.
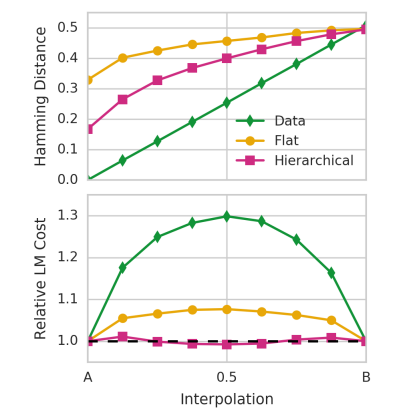
결과 2. Interporlation 에 대한 결과이다.
X 는 A,B 로 균일하게 interporlation 한 결과이고, (z 에서 했다고한다.)
결과적으로 나온 y 축의 결과는 propotion of timestep predictions that differ between the interpolation and seq A (시작점)
이라고한다.
아래는 마찬가지로 Language model cost 라고 하는데, 이게 뭔지..
결과 3
latent space 에서 음원에 특징의 방향을 만들어서 그것을 넣고(좌측), 뺏다는(우측) 실험이였다.
음원특징을 latent vector 로 만든것도 재미있고 각각 그 방향으로 벡터를 넣고 뺐을 때, 해당되는 특성이 얼마나 measure 되는지를 측정했다고한다. 이런시도들 이 너무 재밌고 신기하다고 생각한다.
region-aware depth estimation by enforcing semantics consistency between stereo pairs. E.G sky - high depth 이런식으로 segment 와 depth 를 연결, e leftright semantic consistency and semantics-guided disparity smoothness 를 이용
(근)대량의 학습을 통해 영화등 unlabeled data 에서 평가,loss space 별로 비교(여러가지 나열하고 로스에 대한 평가 부분이 있어서 좋음) ,mixing datasets, multi objective optimization loss 를 dataset 별로 세분화시키는것
(sota2023) data grafting, an exploratory self-distillation loss, nd enhance the representational power of the mode --> streo ->molecure 관점에서 self supervised 로 접근, 지식 총집함이기때문에 첨부터 읽기 힘들수 있음
바로밑의 refer spacing-increasing discretization (SID) strategy to discretize depth and recast depth network earning as an ordinal regression problem, deconv 나 skip connection 을뺏고 ASPP 넣었다. SID 는 로그스케일로 deth map 보는것, ordinal 은 y space 를 퀀타이즈하는것
- 용량만 줄이고 실제 동작 할때는 weight 를 다시 floating point 방식으로 변환하여
- 속도는 full integer quantization 에 비해 저하됨
1.1.2 full integer quantization
- model weight , input, activation 등 모두 quantization 작업을 통해 진행됨
- weight, bias 등은 constant 이기 때문에, 알아서 변한됨
- input, activation (output of activation layer) 의 경우 일종의 sample dataset 을 넣어주면 모델이 변환하는 과정에서 tensor 를 흘려보내면서 변환시키는 구조
- 그러므로 tflite 파일에는 모델의 sample input 을 통해 float32→int8 등으로 변환하는 관계식을 포함시킴
a. 우린 각각의 NN 의 각 layer가 manifold of interest 를 form 한다고 알고있습니다. (명확하진 않지만 통속적으로)
b. 그 때 manifold of interest 는 더 적은 차원의 subspace 에 embedding 될 수 있다고 오랫동안 가정해왔습니다.
c. CNN 에서 독립적인 d개의 체널 pixel 을 보면 information 이 이 곳에 Some manifolod를 형성하며 encoded 되어 있습니다.
d. mobilenet v1 에서도 보앗듯이 width multiplyer manifold of interest 가 dense 하게 span 할 때까지 dimensinality 를 감소시킵니다.
e. 하지만 이것은 NN 이 non-linear transformation 을 포함할 때 깨지게 됩니다. ( 이 논문에서 실험하였음)
f. Relu 를 예를 들자면, 아래와 같이 Relu 의 output 형태를 보면 1차원이기 때문에 output space 를 보면 , piecewise linear curve 를 형성합니다.
f -2 . 이것을 다르게 해석하면 Deep network 는 최종 output activation 에 의해 오직 1차원적인 classifier 로서 동작하게됩니다. 이때 output domain 에서 생각해보면 non-zero volume (finte?) 을 형성하게됩니다.
g. 우리는 추가적으로 input manifold 가 low-dimensional subspace 에 embedding 될 수 있다면, Relu transformation 이
그 information 을 preserve 하는 것을 증명하였습니다. 필요조건이 있는데[그것의 복잡도를 포함하기 위한 set of expressible functions 찾을 수 있다면
이어서 이 정리에 대한 내용만 설명해보자면
S 는 compact, fB = Relu(BX) : Rn => Rm, P(B) = pdf on Matrix
>> 결론, fb 로 부터 유도(collapse~축소)된 m 차원공간 space 의 average n-volume 은,
V - (Nm,n)/ (2^m) V = V(1-(Nm,n)/ (2^m)) = Vol(S) * 0.xxx 즉 처음 정의한 S 라는 compact 공간에 Embedding 된다.
#summary for bottleneck
1. If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
2. ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
(3). Experimental evidence suggests that using linear layers is crucial as it prevents nonlinearities from destroying too much information
1. manifold of interest 가 RELU이후 non zero volume 을 남긴다면, 이것은 linear transform에 대응됨
2. RELU 는 information 을 preserve 할 수 있는 가능성이있다, 하지만 오직 input manifold 가 low -dimensinal subspace 의 lie 될 때만
3. Exprimental 이 증명한다, Linear layer 이 information 이 destroy 되는 것을 막아준다고.
ex
>Bottleneck 은 일종의 최적으로 압축된 Manifold 로 Encoding 된 정보의 집합
ex)CNN , Image recognition 은 2번가정에 매우 적합할 수 밖에 없다.
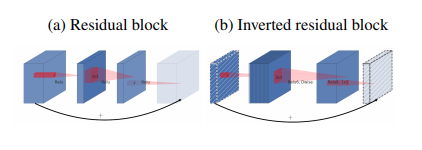
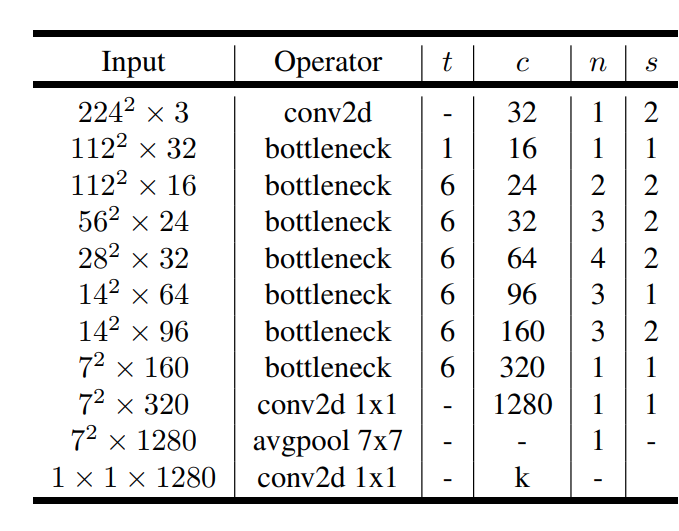
#Inverted Residuals
기존에 있던 Residual bolck 을 반대로 하는것이다.
Residual 에 대해서 먼저 이야기 하자면, Residual 이 사용되는 가장 큰이유는 앞서말한 정보 파괴를 막기 위해 Residual 을 만들어 주게 된다.
하지만 이논문에서는 이것을 반대로 뒤집어서 하게되는데,
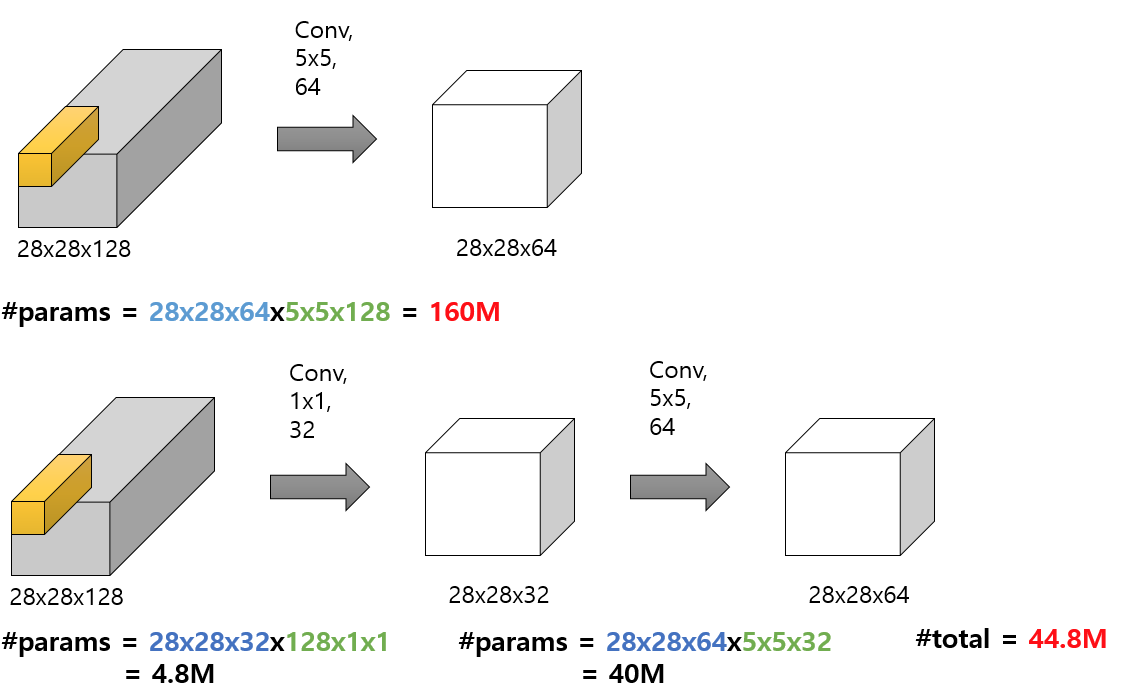
첫번째 가정이 inverted residual block 을 돌리기 이전에 이미 bottleneck 을 만든다는 것이다.
이미 축소된 subspace 로 embedding 시키고 그것을 residual 하게되면 메모리, 연산량 측면에서 많은 이점을 갖게된다.
왜 굳이 conv 할때 expand 하는지에 대해서 묻는다면?
이 channel expand 의 역할은 비선형을 포함 할 수 있도록 도와주는 Detail 의 역할을 한다고한다.
결론적으로 채널수 / memory 수를 비교해보면 더 bottleneck 을 만들어 놨다는 것을 알 수 있다.
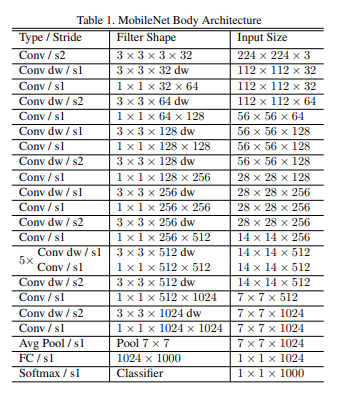
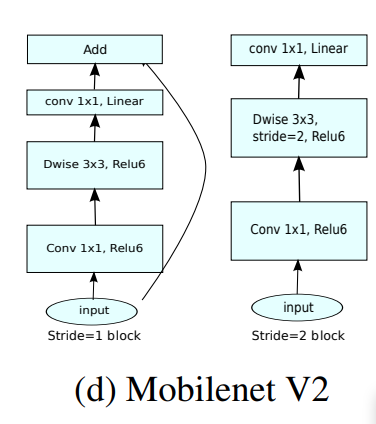
이것을 보면 Stride 가 1/2 일 때 block 이 상이 한데,
Stride 2 는 Residual 이 없는 것을 확인 할 수 있다.
그 말인 즉슨, Resolution 자체가 줄어들 때는, 체널을 넓늘려가며 충분히 information을 담는 parameter 자체는 늘어나도록
신경을 썻고, Stride 1 ,Resolution 자체가 유지될 때는, Inverted Residual 을 넣어 원래 정보를 유지시키는 대 집중 하고, 그안에서 더 높은차원의 data 를 expand and squeeze 를 사용해서 추출해서 detail 로 사용 했다고 보면 된다.
Q 64 >96 160 >320 의 역할은 무엇일까. 오히려 체널을 bottleneck 을 했다가 다시 넓히는 이유가 있을까?